Объектно-ориентированные базы данных
Краткая историческая справка
Разработка систем объектно-ориентированных баз данных (так называемые технологии
баз данных пятого поколения) началась в середине 80-х годов в связи с необходимостью
удовлетворения требований приложений, отличных от тех приложений обработки данных,
которые характерны для систем реляционных баз данных (технология баз данных
четвертого поколения). Попытки использования технологий реляционных баз данных в
таких сложных приложениях, как автоматизированное проектирование (computer aided design, CAD);
автоматизированное производство (computer aided manufacturing, CAM); технология программирования;
системы, основанные на знаниях, и мультимедийные системы, обнажили ограничения систем
реляционных баз данных (РБД). В условиях, когда появилось новое поколение приложений
баз данных, возникли потребности, которые лучшим образом удовлетворялись при
применении объектно-ориентированных баз данных (ООБД).
Университетские исследовательские группы внесли огромный вклад в развитие
технологии баз данных, и не только в области реляционных систем. Многие
университетские исследователи с энтузиазмом приняли объектно-ориентированный подход,
особенно в применении к области человеко-машинных взаимодействий. К наиболее успешным
проектам, в которых производились исследования с целью объединения объектно-ориентированного
подхода с технологией баз данных, можно отнести следующие:
- Encore в Брауновском университете (Broun University);
- Cactis в Колорадском университете (University of Colorado at Boulder);
- Thor в Массачусетском технологическом институте (MIT );
- Exodus в Висконсинском университете (University of Wisconsin );
- Pisa в университетах Глазго и Св. Эндрю (Universities of Glasgo and St. Andrew).
Среди исследовательских институтов, в которых существовали мощные группы,
ориентированные на исследования в области объектно-ориентированных баз данных,
входили OGI (Oregon Graduate Institute), MCC (Microelectronics and Computer Technology Corporation) и французский
исследовательский центр INRIA. На базе исследований OGI была создана ООСУБД Gemstone;
исследования, проводившиеся в MCC, привели к созданию ООСУБД Itasca и UniSQL; в результате
исследовательского проекта Altair, выполнявшегося в INRIA , появилась ООСУБД O2.
Среди наиболее значительных прототипов ООСУБД, созданных в результате исследований,
которые проводились в ведущих компьютерных компаниях, можно выделить систему IRIS
компании Hewlett-Packard и систему Trellis компании DEC. Идеи и методы, заложенные в этих проектах,
были впоследствии использованы в большинстве коммерческих ООСУБД. Тем не менее,
руководители крупных компаний решили не производить коммерческие ООСУБД
самостоятельно, а предоставить эту возможность начинающим компаниям.
Первыми компаниями, выпустившими на рынок ООСУБД в виде законченных продуктов, были
следующие компании:
- Grapael сООСУБД G-Base (1986 г);
- Servio-Logic сООСУБД Gemstone (1987 г.);
- Symbolics сООСУБД Statice (1988 г.);
- Ontologic Ltd. с ООСУБД Vbase (1988 г.).
Ко всем ранним реализациям ООСУБД применительны следующие замечания.
- Системы были почти неприменимы для практического использования, поскольку они
очень медленно работали, поддерживали только однопользовательский режим работы и
были крайне ненадежны. В них не поддерживались распределенные данные, безопасность и
возможность восстановления после сбоев. Почти во всех системах отсутствовали
развитые механизмы формулировки запросов. При построении пользовательских
интерфейсов не использовались даже уже имевшиеся результаты, полученные группами из
области человеко-машинных взаимодействий.
- Разработчики практически всех систем полностью игнорировали язык C++, поскольку
считалось, что применение этого языка в контексте ООСУБД вызывает серьезные
проблемы. В системах G -Base и Statice использовался Lisp; Gemstone опиралась на Smalltalk; для Vbase были
разработаны собственные языки определения данных (TDL) и манипулирования данными (COP).
В исследовательских группах также предпочитали не опираться на C++, а разрабатывать
новые языки, в большей степени соответствующие направлению исследований. Среди
отрицательных последствий игнорирования C++ было то, что пользователей заставляли
изучать новый язык; они вынуждались одновременно использовать два языка; отсутствие
поддержки C++ ограничивало рынок ООСУБД.
Новые компании Objectivity, Object Design и Versant, образованные в конце 80-х, ориентировались на
создание ООСУБД, которые опирались бы на C++. Компания Ontologic отказалась от развития Vbase и
переключилась на разработку системы ONTOS, основанной на C++. В Европе были образованы
компании O2 Technology и BKS Software . Задачей первой компании было создание коммерческой ООСУБД O2
49 на основе результатов проекта Altair. BKS начала разработку системы POET. В 90-е годы для
реализации коммерческих проектов, основанных на результатах MCC, были образованы
компании UniSQL 50 и Itasca.
К концу 90-х существовало около десяти компаний, производящих коммерческие продукты,
позиционируемые на рынке как ООСУБД. Каждый продукт обладал индивидуальными
особенностями, частично определяемыми жизненным опытом разработчиков, но большей
частью проистекающими из требований клиентов компании.
На данный момент известно уже несколько десятков систем управления объектно-ориентированными
базами данных (например, система GemStone компании Servio, ONTOS компании Ontos, ObjectStore компании Object
Design и многие другие. Кроме того, системы управления реляционными базами данных,
разработанные компаниями Oracle, Microsoft, Borland, Informix, включали объектно-ориентированные
средства), однако назвать какую-либо из них достаточно совершенной нельзя. По этой
причине, возможно, ООБД не получили на сегодняшний день достаточного распространения.
Что такое объектно-ориентированные базы данных
Причиной появления систем объектно-ориентированных баз данных была потребность в
более адекватном представлении и моделировании сущностей реального мира, поскольку
ООБД обеспечивают гораздо более развитую модель данных, нежели традиционные —
реляционные базы данных. Парадигма ООБД основывается на ряде базовых понятий, таких
как объект, идентифицируемость, класс, наследование, перегрузка и отложенное
связывание.
В объектно-ориентированной модели данных любая сущность реального мира
представляется всего одним понятием — объектом. С объектом ассоциируется
состояние и поведение. Состояние объекта определяется значениями его свойств — атрибутов.
Значениями свойства могут являться примитивные значения (такие, как строки или целые
числа) и непримитивные объекты. Непримитивный объект, в свою очередь, состоит из набора
свойств. Следовательно, объекты можно рекурсивно определять в терминах других
объектов. Поведение объекта определяется с помощью методов, которые оперируют над
состоянием объекта.
У каждого объекта имеется определяемый системой уникальный идентификатор.
Объекты, обладающие одними и теми же свойствами и поведением, группируются в классы.
Объект может быть экземпляром только одного класса или нескольких классов.
В подавляющем большинстве реализаций ООБД лежат такие киты:
- Абстракция: Каждая реальная "вещь", которая хранится в БД, является членом
какого-либо класса. Класс определяется как совокупность свойств (properties), методов
(methods), общедоступных (public) и частных (private) структур данных, а также программы,
применимых к объектам (экземплярам) данного класса. Классы представляют собой ни что
иное, как абстрактные типы данных. Методы - это процедуры, которые вызывается для того,
чтобы произвести какие-либо действия с объектом (например, напечатать себя или
скопировать себя). Свойства - это значения данных, связанные с каждым объектом класса,
характеризующие его тем или иным образом (например, цвет, возраст). Свойства
присутствуют не во всех реализациях, по сути дела, они являются краткой записью
методов без аргументов (таких как "сообщите свой цвет", "сообщите свой возраст").
- Инкапсуляция: Внутреннее представление данных и деталей реализации
общедоступных и частных методов (программ) является частью определения класса и
известно только внутри этого класса. Доступ к объектам класса разрешен только через
свойства и методы этого класса или его родителей (см. ниже "наследование"), а не
путем использования знания подробностей внутренней реализации.
- Наследование (одиночное или множественное): Классы определены как часть
иерархии классов. Определение каждого класса более низкого уровня наследует
свойства и методы его родителя, если они только они явно не объявлены ненаследуемыми
или изменены новым определением. При одиночном наследовании класс может иметь
только один родительский класс (т.е. классовая иерархия имеет древовидную структуру).
При множественном наследовании класс может происходить от многочисленных родителей
(т.е. иерархия классов имеет структуру ориентированного нециклического графа, не
обязательно древовидную). Не все объектно-ориентированные СУБД поддерживают
множественное наследование.
- Полиморфизм: Несколько классов могут иметь совпадающие имена методов и свойств,
даже если они считаются различными. Это позволяет писать методы доступа, которые
будут правильно работать с объектами совершенно различных классов, лишь бы
соответствующие методы и свойства были в этих классах определены. Например, метод Print
может быть определен во многих классах, но работать по-разному, в зависимости от
класса объекта, к которому он применяется.
- Сообщения: Взаимодействие c объектами осуществляется путем посылки сообщений с
возможностью получения ответов. Это отличается от традиционного для других моделей
вызова процедур. Для того, чтобы применить метод к объекту, надо послать ему
сообщение типа "примени к себе данный метод" (например, "напечатай себя").
Парадигма пересылки сообщений не всегда используется в объектно-ориентированных
базах данных, однако типична для "истинно" ОО-реализаций.
Стандарт ODMG
Первый манифест формально являлся всего лишь статьей, представленной на Конференцию
по объектно-ориентированным и дедуктивным базам данных группой частных лиц. В 1991 г. был
образован консорциум ODMG (тогда эта аббревиатура раскрывалась как Object Database Management
Group, но впоследствии приобрела более широкую трактовку – Object Data Management Group).
Консорциум ODMG тесно связан с гораздо более многочисленным консорциумом OMG (Object
Management Group), который был образован двумя годами раньше. Основной исходной целью ODMG была
выработка промышленного стандарта объектно-ориентированных баз данных (общей модели).
За основу была принята базовая объектная модель OMG COM (Core Object Model). В течение более
чем десятилетнего существования ODMG опубликовала три базовых версии стандарта,
последняя из которых называется ODMG 3.0.
Архитектура
Предлагаемая ODMG архитектура показана на рисунке. В этой архитектуре определяются
способ хранения данных и разные виды пользовательского доступа к этому “хранилищу
данных”. Единое хранилище данных доступно из языка определения данных, языка запросов
и ряда языков манипулирования данными. ODL означает Object Definition Language (язык
определения объектов), OQL – Object Query Language (язык объектных запросов) и OML – Object
Manipulation Language (язык манипулирования объектами).
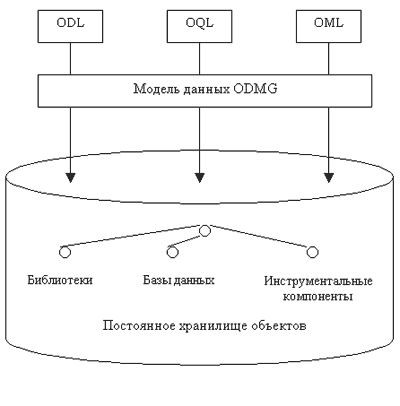
Центральной в архитектуре является модель данных, представляющая
организационную структуру, в которой сохраняются все данные, управляемые ООСУБД. Язык
определения объектов, язык запросов и языки манипулирования разработаны таким образом,
что все их возможности опираются на модель данных. Архитектура допускает
существование разнообразных реализационных структур для хранения моделируемых
данных, но важным требованием является то, что все программные библиотеки и все
поддерживающие инструментальные средства обеспечиваются в объектно-ориентированных
рамках и должны сохраняться в согласовании с данными.
Основными компонентами архитектуры являются следующие:
- Объектная модель данных. Все данные, сохраняемые ООСУБД, структуризуются в
терминах конструкций модели данных. В модели данных определяется точная семантика
всех понятий.
- Язык определения данных (ODL). Схемы баз данных описываются в терминах языка ODL, в
котором конструкции модели данных конкретизируются в форме языка определения. ODL
позволяет описывать схему в виде набора интерфейсов объектных типов, что включает
описание свойств типов и взаимосвязей между ними, а также имен операций и их
параметров. ODL не является полным языком программирования; реализация типов должна
быть выполнена на одном из языков категории OML. Кроме того, ODL является виртуальным
языком в том смысле, что в стандарте ODMG не требуется его реализация в программных
продуктах ООСУБД, которые считаются соответствующими стандарту. Допускается
поддержка этими продуктами эквивалентных языков определения, включающих все
возможности ODL, но адаптированных под особенности конкретной системы. Тем не менее,
наличие спецификации языка ODL в стандарте ODMG является важным, поскольку в языке
конкретизируются свойства модели данных.
- Язык объектных запросов (OQL). Язык имеет синтаксис, похожий на синтаксис языка SQL,
но опирается на семантику объектной модели ODMG . В стандарте допускается прямое
использование OQL и его встраивание в один из языков категории OML.
- Языки манипулирования объектами (OML). Для программирования реализаций операций
и приложений требуется наличие объектно-ориентированного языка программирования. OML
представляется собой интегрирование языка программирования с моделью ODMG; это
интегрирование производится за счет определенных в стандарте правил языкового
связывания (language binding). Дело в том, что в самих языках программирования, естественно,
не поддерживается стабильность объектов. Чтобы разрешить программам на этих языках
обращаться к хранимым данным, языки должны быть расширены дополнительными
конструкциями или библиотечными элементами. Эту возможность и обеспечивает
языковое связывание.
В одной ООСУБД могут поддерживаться несколько OML.
- Постоянное хранилище объектов. Логическая организация хранилища данных любой
ООСУБД, совместимой со стандартом ODMG, должна основываться на модели данных ODMG.
Физическая организация у разных ООСУБД может различаться, но в любом случае она
должна обеспечивать эффективные структуры данных для хранения иерархии типов и
объектов, являющихся экземплярами этих типов. Иерархия типов связана не только с
данными, но и с различными библиотеками и компонентами инструментальных средств,
поддерживающими разработку приложений. Так что в ООСУБД, совместимой со стандартом
ODMG , хранилище представляет собой интегрированную систему, где согласованным
образом сохраняются данные и программный код.
- Инструментальные средства и библиотеки. Инструментальные средства,
поддерживающие, например, разработку пользовательских приложений и их графических
интерфейсов, программируются на одном из OML и сохраняются как часть иерархии классов.
Библиотеки функций доступа, арифметических функций и т.д. также сохраняются в
иерархии типов и являются единообразно доступными из программного кода
разработчика приложения. Ассортимент инструментальных средств и библиотек в
стандарте не определяется.
Объектная модель
Модель ODMG является объектной моделью данных, включающей возможность описания как
объектов, так и литеральных значений. На разработку модели повлиял тот факт, что она
предназначена для поддержки работы с базами данных, так что особо важной является
эффективность доступа к данным. Большинство других объектных моделей ориентировано на
языки программирования, рассчитанных на работу со всеми данными в основной памяти. В
этом случае допустимо представлять все данные как объекты. Но если требуется управлять
большим объемом данных, расположенных во внешней памяти, то требуется некоторый
компромисс между “чистотой” модели и требуемой эффективностью. Модель ODMG
подстраивается под специфику систем баз данных следующим образом:
- Для баз данных, схем и подсхем обеспечивается набор встроенных объектных типов.
- Модель включает ряд встроенных структурных типов, позволяющих применять
традиционные методы моделирования баз данных.
- Модель одновременно включает понятия объектов и литералов.
- В модели связи между объектами отличаются от атрибутов.
Объекты и литералы
Как утверждалось в Первом манифесте, одним из важнейших отличий объектов от
значений является наличие у объекта уникального идентификатора. Накладные расходы,
требуемые для обращения к объекту по его идентификатору с целью получения доступа к
базовым значениям данных, могут весьма сильно замедлить работу приложений. Поэтому в
модели ODMG допускается описание всех данных в терминах объектов и использование
традиционного вида значений, которые в модели называются литеральными значениями.
Таким образом, возраст человека может задаваться целочисленным литералом, а не
объектом, имеющим свойство возраст. В этом случае значение возраста будет
сохраняться как часть структуры данных объекта человек, а не в отдельном объекте.
Это, в частности, означает, что объект может входить в состав нескольких других
объектов, а литерал – нет. Схема базы данных в модели ODMG главным образом состоит из
набора объектных типов, но компонентами этих типов могут быть типы литеральных
значений.
Другим понятием, используемым для различения объектов и литералов, является понятие
изменчивости (mutability). Предположим, например, что данные о человеке составляют
структуру <имя, возраст, адрес_проживания>. Тогда возможны два варианта хранения
этих данных:
Если человек представляется в виде объекта, то компоненты описывающей его структуры
данных могут изменяться (например, может изменяться адрес), но объект (человек) остается
тем же самым (поскольку объектный идентификатор не изменяется). Тем самым, объекты
обладают свойством изменчивости.
Если же данные о человеке сохраняются в виде литеральной структуры, и один из
компонентов этой структуры изменяется, то вся структура трактуется как новое значение.
Если данные о человеке не должны изменяться, то не может изменяться ни один элемент
структуры, и она является неизменчивым литералом.
Другими словами, объект идентифицируется своим объектным идентификатором (OID – Object
Identifier), который полностью отделен от значений компонентов объекта, а литерал
полностью идентифицируется значениями своих компонентов.
Связи
В большинстве объектных систем связи неявно моделируются как свойства, значениями
которых являются объекты. Например, если человек работает на некоторую компанию, то у
каждого объекта-человека должно иметься свойство, которое можно назвать worksFor и
значением которого является соответствующий объект-компания. Возникает проблема, если
у объекта-компании имеется свойство, которое затрагивает множество служащих этой
компании (например, employees – множество, включающее все объекты служащих данной
компании). Эти два свойства являются несвязными, и поддержка их согласованности может
вызывать значительную программистскую проблему.
В модели ODMG различаются два вида свойств – атрибуты и связи, хотя и несколько другим
образом. Атрибутами называются свойства объекта, значение которых можно получить
по OID объекта, но не наоборот. Значениями атрибутов могут быть и литералы, и объекты, но
только тогда, когда не требуется обратная ссылка. Связи – это инверсные свойства. В
этом случае значением свойства может быть только объект, поскольку литеральные
значения не обладают свойствами. Поэтому возраст служащего обычно моделируется как
атрибут, а компания, в которой работает служащий, – как связь.
При определении связи должна быть определена ее инверсия. В приведенном выше примере,
если worksFor определяется как связь, должно быть явно указано, что инверсией является
свойство employees объекта-компании, а при определении employees должна быть указана
инверсия worksFor . После этого система баз данных должна поддерживать согласованность
связанных данных, что позволяет сократить объем работы программистов приложений и
повысить надежность их программ. Если в объекте-компании свойство employees не
требуется, то свойство объекта-служащего employees может быть атрибутом.
Объектные и литеральные типы
В модели ODMG база данных представляет собой коллекцию различимых значений (denotable values)
двух видов – объекты и литералы. Объекты обладают свойствами идентифицируемости и
индивидуального существования, а литералы являются компонентами объектов. Модель
данных содержит конструкции для спецификации объектных и литеральных типов. Объектные
типы существуют в иерархии объектных типов; литеральные типы похожи на типы,
характерные для обычных языков программирования. В модели ODMG не используется термин
класс. Единственная классификационная конструкция называется типом, и типы описывают
как объекты, так и литералы. То, что называлось классом в Первом манифесте, в ODMG
называется объектным типом.
В модели поддерживается ряд литеральных типов – базовые скалярные числовые типы,
символьные и булевские типы (атомарные литералы), конструируемые типы литеральных
записей (структур) и коллекций. Конструируемые литеральные типы могут основываться на
любом литеральном или объектном типе, но считаются неизменчивыми. Даты и время
строятся как литеральные структуры.
Объектный тип состоит из интерфейса и одной или нескольких реализаций. Интерфейс
описывает внешний вид типа: какими свойствами он обладает, какие в нем доступны
операции и каковы параметры у этих операций. В реализации определяются структуры
данных, реализующие свойства, и программный код, реализующий операции. Интерфейс
составляет общедоступную (public) часть типа, а в реализации при необходимости могут
вводиться дополнительные частные (private) свойства и операции. Все объектные типы (системные
или определяемые пользователем) образуют решетку (lattice) типов, в корне которой
находится предопределенный объектный тип Object. Чтобы не объяснять подробно, что
такое решетка, приведем пример графа, являющегося решеткой.
Ограничимся рассмотрением интерфейсной части типа. Интерфейс объектного типа
состоит из следующих компонентов:
- имя;
- набор супертипов (предков, если поддерживается множественное наследование);
- имя поддерживаемого системой экстента;
- один или более ключей для ассоциативного доступа;
- набор атрибутов, каждый из которых может быть объектом или литеральным значением;
- набор связей, каждая из которых указывает на некоторый другой объект;
- набор операций.
Атрибуты и связи совместно называются свойствами, а свойства и операции совместно
называются характеристиками объектного типа (или объектов данного типа).
Точно так же, как имеются атомарные и конструируемые литеральные типы, существуют
атомарные и конструируемые объектные типы. В стандарте ODMG 3.0 говорится, что атомарными
объектными типа являются только типы, определяемые пользователями. Конструируемые
объектные типы включают структурные типы и набор типов коллекций.
Язык определения объектов ODL
ODL является языком определения данных для объектной модели ODMG. ODL используется
исключительно для описания интерфейсов типов приложения, а не для программирования
реализации. Это не язык программирования, а всего лишь язык описания схем баз данных.
“Программа” на языке ODL – это набор определений типов, констант, исключительных
ситуаций, интерфейсов типов и модулей. Не углубляясь в детали и не приводя
синтаксических правил, остановимся на наиболее интересных особенностях ODL.
Язык обеспечивает исключительно мощные возможности для определения литеральных
типов. Можно определить четыре разновидности типов коллекций. Типы категории set –
это обычные типы множеств. Типы категории bag – эти типы мультимножеств (в значениях
которых допускается наличие элементов-дубликатов). Значениями типов категории list
являются упорядоченные списки значений (среди них допускаются дубликаты). Наконец,
значениями типы dictionary являются множества пар <ключ, значение>, причем все ключи в
этих парах должны быть различными. Определения типов имеют рекурсивную природу.
Например, можно определить тип множества структур, элементами которых будут являться
списки мультимножеств и т.д.
Синтаксические правила, относящиеся к определению объектных типов, требуют достаточно
подробных разъяснений. К сожалению, в стандарте ODMG 3.0 этих разъяснений явно
недостаточно.
Во-первых, объектный тип можно определить с помощью двух разных синтаксических
конструкций языка ODL – interface и class. Определение класса отличается от определения
интерфейса наличием двух необязательных разделов: extends и type_property_list. В
действительности, наиболее важным отличием класса от интерфейса является возможность
наличия второго из этих разделов. В списке свойств могут присутствовать элементы extent
и key. В спецификации модели данных ODMG 3.0 (хотя это и не отражается явно в синтаксисе
ODL) говорится, что для каждого класса может быть определен только один экстент,
являющийся множеством всех объектов этого класса, которые после создания должны
сохраняться в базе данных.
Ключ – это набор свойств объектного класса, однозначно идентифицирующий состояние
каждого объекта, входящего в экстент класса (это аналог возможного ключа реляционной
модели данных). Для класса может быть объявлено несколько ключей, а может не быть
объявлено ни одного ключа даже при наличии определения экстента. В последнем случае в
экстенте класса могут существовать разные объекты с одним и тем же состоянием.
Далее, хотя и интерфейсы, и классы являются средствами определения объектных типов,
между ними проводится жесткое различие. Допускается создание объектов только тех
объектных типов, которые определены как классы. Объектные типы, определенные как
интерфейсы, могут использоваться только для порождения новых объектных типов (интерфейсов
и классов) на основании (вообще говоря) множественного наследования. Классы могут
определяться на основе (вообще говоря) множественного наследования интерфейсов и
одиночного наследования классов.
Механизм наследования от интерфейсов называется в ODMG наследованием IS-A, а механизм
наследования от классов – extends. Прежде чем попытаться пояснить этот подход,
приведем пример графа наследования интерфейсов и классов, в котором также
показывается место существующих экстентов и объектов.
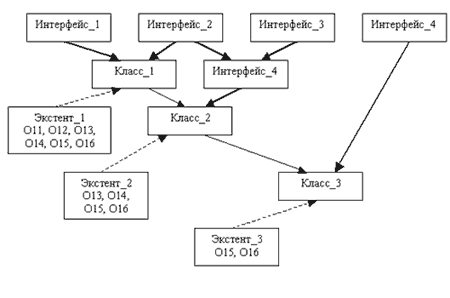
Пример иерархии объектных типов и их экстентов
На рисунке “жирными” стрелками показаны связи объектных типов по наследованию IS-A .
Обычные стрелки показывают связи по наследованию extends . Пунктирные стрелки
соответствуют связям экстентов и соответствующих классов. Обратите внимание, что на
этом рисунке у каждого из классов, входящих в иерархию, определен свой собственный
экстент. Как демонстрирует рисунок, в модели ODMG поддерживается семантика включения,
означающая, что экстент любого подкласса является подмножеством экстента любого
своего суперкласса (прямого или косвенного). Если у некоторого подкласса свой
собственный экстент не определен, то с объектами этого подкласса можно работать только
через экстент какого-либо суперкласса. Стандарт не требует обязательного определения
экстента. В этом случае ответственность на поддержку работы с множествами объектов
ложится на прикладного программиста (для этого можно использовать типы коллекций).
Итак, при порождении подкласса путем наследования extends от некоторого суперкласса
подкласс наследует экстент и набор ключей суперкласса. Как мы уже заметили, для
подкласса можно определить свой собственный экстент. Что же касается возможности
переопределения ключей, то в стандарте отсутствуют явные указания о возможности или
невозможности этого действия. Однако очевидно, что если бы было разрешено полное
переопределение набора ключей для экстента подкласса, то это противоречило бы
семантике включения.
Теперь немного поговорим о связях. Связи определяются между объектными типами. В
модели ODMG поддерживаются только бинарные связи, т.е. связи между двумя типами. Связи
могут быть разновидностей “один-к-одному”, “один-ко-многим” и “многие-ко-многим” в
зависимости от того, сколько экземпляров соответствующего объектного типа может
участвовать в связи.
Связи явно определяются путем указания путей обхода (traversal paths). Пути обхода
указываются парами, по одному пути для каждого направления обхода связи. Например, в
базе данных “служащие-отделы-проекты” служащий работает (works) в одном отделе, а
отдел состоит (consists of) множества служащих. Тогда путь обхода consists_of должен быть
определен в объектном типе DEPT , а путь обхода works – в типе EMP. Тот факт, что пути
обхода относятся к одной связи, указывается в разделе inverse обоих объявлений пути обхода.
В нашем случае определения типов DEPT и EMP могли бы выглядеть следующим образом:
class DEPT {
...
relationship set <EMP> consists_of
inverse EMP :: works
... }
class EMP {
...
relationship DEPT works
inverse DEPT :: consists_of
... }
Как видно, это связь “один-ко-многим”. Путь обхода consists_of ассоциирует экземпляр типа
DEPT со множеством экземпляров типа EMP, а путь обхода works ассоциирует экземпляр типа EMP с
экземпляром типа DEPT. Пути обхода, ведущие к коллекциям объектов, могут быть
упорядоченными или неупорядоченными в зависимости от вида коллекции, указанному в
объявлении пути обхода. В приведенном выше примере consists_of является неупорядоченным
путем обхода.
В ООСУБД, соответствующей стандарту ODMG , должна поддерживаться ссылочная целостность
связей. Это означает, что при ликвидации любого объекта, участвующего в связи, должны
ликвидироваться и все пути обхода, ведущие к этому объекту. Такой подход гарантирует,
что приложения не смогут воспользоваться путями обхода, ведущими к несуществующим
объектам.
Наконец, хотя это явно не отражено в синтаксисе языка ODL, наряду с набором генераторов
литеральных типов коллекций set < t >, bag < t >, list < t >, array < t > и dictionary
< t , v > поддерживается аналогичный набор генераторов объектных типов коллекций – Set
< t >, Bag < t >, List < t >, Array < t > и Dictionary < t , v >. В отличие от
литералов-коллекций объекты-коллекции обладают объектными идентификаторами и
свойством изменчивости. Во всех случаях требуется, чтобы все элементы коллекции были
одного типа, литерального или объектного. И для литеральных, и для объектных коллекций
поддерживается возможность итерации коллекции с перебором элементов коллекции либо в
порядке, определяемом системой (для множеств и мультимножеств), либо в порядке,
предполагаемом видом коллекции (для списков, массивов и словарей).
Язык запросов OQL
Краткая характеристика языка запросов OQL
В кратком и неформальном описании языка мы будем по возможности строго следовать
манере и последовательности изложения, принятым в стандарте ODMG 3.0, меняя только примеры.
Разработчики языка основывались на следующих основных принципах:
- OQL опирается на объектную модель ODMG.
- OQL очень близок к SQL/92. Расширения относятся к объектно-ориентированным понятиям,
таким как сложные объекты, объектные идентификаторы, путевые выражения, полиморфизм,
вызов операций и отложенное связывание.
- В OQL обеспечиваются высокоуровневые примитивы для работы с множествами объектов, но,
кроме того, имеются настолько же эффективные примитивы для работы со структурами,
списками и массивами.
- OQL является функциональным языком, допускающим неограниченную компонируемость
операций, если операнды не выходят за пределы системы типов. Это является следствием
того факта, что результат любого запроса обладает типом, принадлежащим к модели
типов ODMG, и поэтому к результату запроса может быть применен новый запрос.
- OQL не является вычислительно полным языком. Он представляет собой простой язык
запросов.
- Операторы языка OQL могут вызываться из любого языка программирования, для которого
в стандарте ODMG определены правила связывания. И наоборот, в запросах OQL могут
присутствовать вызовы операций, запрограммированных на этих языках.
- В OQL не определяются явные операции обновления, а используются вызовы операций,
определенных в объектах для целей обновления.
- В OQL обеспечивается декларативный доступ к объектам. По этой причине OQL -запросы
могут быть легко оптимизированы.
- Можно легко определить формальную семантику OQL.
Входные данные и результаты запросов
Как утверждается в стандарте ODMG 3.0, “OQL-запрос является функцией, вырабатывающей
объект, тип которого может быть выведен на основе операций, которые участвуют в
выражении запроса”. Вот несколько примеров простых OQL-запросов (мы будем использовать
в этих примерах определенные в предыдущем подразделе классы DEPT и EMP в предположении,
что DEPARTMENTS и EMPLOYEES являются именами экстентов этих классов).
Пример 1. Найти даты рождения служащих, зарплата которых превышает 20000 руб.
SELECT DISTINCT
E.EMP_BDATE
FROM
EMPLOYEES E
WHERE
E.EMP_SAL > 20000.00
Легко видеть, что этот запрос по своему виду ничем не отличается от соответствующего
запроса к таблице EMP, выраженного на языке SQL . В данном случае результатом запроса будет
литеральное значение типа set < date > , т.е. литеральное значение-множество, элементами
которого являются значения типа date.
Пример 2. Найти имена и даты рождения служащих, зарплата которых превышает 20000 руб.
SELECT DISTINCT STRUCT
(name: E.EMP_NAME, bdate: E.EMP_BDATE)
FROM
EMPLOYEES E
WHERE
E.EMP_SAL > 20000.00
Запрос снова очень похож на соответствующий запрос на языке SQL, а результатом запроса
является литеральное значение-множество, элементами которого являются значения типа
struct { string <20> name ; date bdate }. Наверное, для конечного пользователя языка OQL строгий вывод
типа результата запроса может показаться избыточным, но для программистов приложений
это свойство является очень важным.
Если предположить, что в классе EMP определена операция age, значением которой является
возраст соответствующего служащего, то результатом запроса
SELECT DISTINCT STRUCT
(name: E.EMP_NAME, age: E.age)
FROM
EMPLOYEES E
WHERE
E.EMP_SAL > 20000.00
будет литеральное значение-множество, элементами которого являются значения типа
struct { string <20> name ; interval age }.
Пример 3. Получить номера менеджеров отделов и тех сотрудников их отделов,
зарплата которых превышает 20000 руб.
SELECT DISTINCT STRUCT
(mng: D.DEPT_MNG, DHS: (SELECT
E
FROM
D.CONSISTS_OF AS E
WHERE
E.EMP_SAL > 20000.00))
FROM DEPARTMENTS D
Внешне этот запрос снова похож на SQL-запрос с вложенным подзапросом, но это только
внешнее сходство. Во-первых, в разделе FROM “подзапроса” мы имеем дело с переходом по
связи CONSISTS_OF от экземпляра объектного типа DEPT ко множеству экземпляров объектного типа
EMP . Во-вторых, результатом запроса является литеральное значение-множество, элементами
которого являются значения-структуры с двумя литеральными значениями, первое из
которых есть атомарное литеральное значение типа INTEGER , а второе – литеральное
значение-множество с элементами-объектами типа EMP. Более точно, результат запроса имеет
тип set < struct { integer mng ; bag < EMP > DHS } >. Конечно, в “классическом” SQL такого быть не может,
хотя далее будут рассмотрены возможности объектно-реляционных расширений этого языка.
В OQL предполагается, что хранимые в базе данных объекты могут иметь индивидуальные
имена.
Пример 4. Если, например, в базе данных сохраняется объект типа DEPT с именем
main_department, то результатом запроса
main_department
будет являться соответствующий объект. Результатом запроса
main_department.CONSISTS_OF
будет литеральное значение-множество, состоящее из объектов типа EMP , ассоциированных
через связь CONSISTS_OF с объектом main_department.
Наконец, в контексте OQL имя каждого экстента можно трактовать как имя объекта-множества.
Поэтому результатом запроса
EMPLOYEES
будет литеральное множество, состоящее из всех объектов, которые содержаться в
указанном экстенте.
Объекты как результаты запросов
В примерах предыдущего пункта результатами запросов являлись литеральные значения,
не обладающие объектными идентификаторами. Если ввести следующие определения
объектных типов:
typedef Set <interval> ages;
class persinfo {
attribute string <20> n;
attribute date b; };
typedef Bag <persinfo > info;
то можно сформулировать следующие запросы.
Пример 5.
ages (SELECT DISTINCT
E.age
FROM
EMPLOYEES E
WHERE
E.EMP_SAL > 20000.00)
Окончательным результатом этого запроса является объект-множество, включающий
литеральные значения типа interval.
Пример 6.
info (SELECT
persinfo (n: E.EMP_NAME, b: E.EMP_BDATE)
FROM
EMPLOYEES E
WHERE
E.EMP_SAL > 20000.00)
В этом примере по литеральным значениям имени и даты рождения каждого служащего,
размер зарплаты которого превышает 20000 руб., конструируется объект типа persinfo , а на
основе литерального мультимножества этих объектов конструируется объект-мультимножество
типа info.
В совокупности результатом допустимых в OQL выражений запросов могут являться:
- коллекция объектов;
- индивидуальный объект;
- коллекция литеральных значений;
- индивидуальное литеральное значение.
Путевые выражения
Для навигации между подобъектами сложных объектов и по связям между разными
объектами в OQL поддерживается специальный вид выражений, называемых путевыми (path
expression). Эти выражения определяются в так называемой точечной нотации (вместо
операции “.” можно использовать и операцию “->”). Рассмотрим несколько
простых примеров. Предположим, что в классах DEPT и EMP , кроме связи CONSISTS_OF - WORKS определена
еще и связь “один-к-одному” MANAGED_BY - MANAGER_OF:
class DEPT {
...
relationship EMP managed_by
inverse EMP :: manager_of
... }
class EMP {
...
relationship DEPT manager_of
inverse DEPT :: managed_by
... }
Пример 7. Для получения объекта типа EMP , соответствующего менеджеру отдела
main_department достаточно написать выражение
main_department.managed_by
Если же требуется получить имя менеджера отдела main_department , то можно воспользоваться
путевым выражением
main_department.managed_by.EMP_NAME
Пример 8. Получить имена всех сотрудников отдела main_department.
Кажется, что запрос очень похож на предыдущий, и что для него годится выражение
main_department.consists_of.EMP_NAME
Но в данном случае мы имеем связь “один-ко-многим”, и хотя у каждого служащего
имеется только одно имя, такие путевые выражения в OQL не допускаются. Правильной
формулировкой запроса является следующая:
SELECT
E.EMP_NAME
FROM
main_department.consists_of AS E
Предикаты и логические операции
В спецификации OQL , как и в стандарте языка SQL , термин предикат обозначает условное
выражение, которое может участвовать в запросе. Но семантика похожих на SQL конструкций
языка OQL существенно отличается, что мы покажем в следующем примере.
Пример 9. Получить номера отделов и имена сотрудников отделов, с размером зарплаты,
большим 10000 руб., работающих в отделах с числом сотрудников, большим 40 человек, и со
средним размером зарплаты, большим 20000 руб.
SELECT STRUCT
(DEPT_NO : D.DEPT_NO, EMP_NAME : E.EMP_NAME )
FROM
DEPARTMENTS D,
D.CONSISTS_OF E
WHERE
D.DEPT_EMP_NO > 40
AND AVG(E.EMP_SAL) > 20000.00
AND E.EMP_SAL > 10000.00
Как следует понимать семантику выполнения данного запроса? Образуется внешний цикл
по просмотру объектов экстента DEPARTMENTS . Для каждого из этих объектов по связи CONSISTS_OF
образуется коллекция (в данном случае, множество) объектов, входящих в экстент EMPLOYEES .
Тем самым, выполняется неявная факторизация (группирование) экстента EMPLOYEES , в которой
инвариантом группы служащих является их общий отдел. По этому поводу в списке выборки и
в условии выборки (предикате) разрешается использовать как свойства инварианта группы
(в нашем случае, DEPT.DEPT_NO и DEPT.DEPT_EMP_NO) и индивидуальные свойства членов групп (в нашем
случае, EMP.EMP_NAME и EMP.EMP_SAL), так и “агрегатные” свойства группы в целом (в нашем случае, AVG
(EMP.EMP_SAL)). Для каждой группы, образуемой во внешнем цикле, оцениваются условия,
характеризующие группу в целом. В просмотр внутреннего цикла допускаются только те
группы, для которых результатом вычисления условий “группы” было true . За каждым
элементом “отобранной” группы сохраняются свойства ее объекта-инварианта.
Как видно даже из этого примера, предикаты раздела WHERE OQL -запросов могут представлять
собой произвольно сложное булевское выражение, в котором простые условия связываются
логическими операциями AND, OR и NOT. Очевидно, что этот набор операций является избыточным.
Тем не менее, в OQL введены две дополнительные логические операции – ANDTHEN и ORELSE. Если X и Y
являются логическими выражениями, то при вычислении выражения X ANDTHEN Y выражение Y
вычисляется (и определяет общий результат) в том и только в том случае, когда
результатом вычисления выражения X является true. Аналогично, при вычислении выражения X
ORELSE Y выражение Y вычисляется (и определяет общий результат) в том и только в том случае,
когда результатом вычисления выражения X является false . Другими словами, таблицы
истинности операций ANDTHEN и ORELSE полностью совпадают с таблицами истинности операций AND и
OR соответственно, но предписывается порядок вычислений. Стандарт ODMG 3.0 не обеспечивает
подробного обоснования для введения этих операций, однако, по нашему мнению, это как-то
связано с желанием остаться в рамках двухзначной логики при возможности наличия
неопределенных значений. Вот пример запроса, в предикате которого можно сравнительно
осмысленно использовать операцию ANDTHEN.
Пример 10. Получить имена служащих и номера их отделов для служащих, работающих в
отделах с фондом заработной платы, размер которого превышает 1000000 руб.
SELECT STRUCT
(name: E.EMP_NAME, dept: D.DEPT_NO)
FROM
EMPLOYEES E,
E.WORKS D
WHERE
E.WORKS != nil
ANDTHEN D.DEPT_TOTAL_SAL > 1000000.00
Кратко затронем тему запросов с соединениями. Должно быть понятно, что введение
механизма связей в языки ODL и OQL главным образом связано с желанием отказаться от явных
естественных соединений. Тем не менее, может возникнуть потребность в явных
соединениях коллекций, объекты или литералы которых связываются по значениям. Вот
простой пример.
Пример 11. Выбрать всех служащих, у которых имеются однофамильцы.
SELECT DISTINCT
E
FROM
EMPLOYEES E,
EMPLOYEES E1
WHERE
E != E1
AND E.EMP_NAME = E1.EMP_NAME
В результате будет образовано литеральное множество, элементами которого являются
объекты типа EMP , для которых в экстенте EMPLOYEES имеется хотя бы один иной (с другим
объектным идентификатором) объект, с тем же значением свойства EMP_NAME . Понятно, что этот
запрос и по виду, и по семантике выполнения является в чистом виде SQL-запросом (если
заменить конструкцию E != E1 на E.EMP_NO <> E1.EMP_NO).
Неопределенные значения
Поддержка неопределенных значений является одной из наиболее запутанных проблем
современной технологии баз данных. ODMG тщательно обходит проблему неопределенных
значений и пытается свести ее к проблеме неопределенных идентификаторов объектов.
Опишем подход ODMG с минимальными комментариями.
Результатом выборки свойства объекта с пустым идентификатором является специальное
значение UNDEFINED . В OQL UNDEFINED считается специальным литеральным значением, входящим во
множество значений любого литерального или объектного типа. Правила обращения со
значением UNDEFINED состоят в следующем:
- Результатом операции is_undefined (UNDEFINED) является логическое значение true.
- Результатом операции is_defined (UNDEFINED) является логическое значение false.
- Если при вычислении предиката раздела WHERE OQL-запроса получается значение UNDEFINED , то
оно трактуется таким же образом, если бы результатом было значение false.
- UNDEFINED является допустимым элементом любой явно или неявно конструируемой коллекции.
- UNDEFINED является допустимым выражением при вычислении агрегатной функции COUNT.
- Результатом любой другой операции, включающей хотя бы один операнд со значением
UNDEFINED , является UNDEFINED.
Пример 12. Найти номера отделов всех сотрудников.
SELECT
E.WORKS.DEPT_NO
FROM
EMPLOYEES E
Результатом запроса будет мультимножество литералов, среди которых будет
содержаться значение UNDEFINED для всех сотрудников, не прикрепленных к какому-либо отделу.
Пример 13. Найти всех сотрудников, прикрепленных к какому-либо отделу.
SELECT
E
FROM
EMPLOYEES E
WHERE
is_defined(E.WORKS.DEPT_NO)
Такой же результат был бы выдан при выполнении запроса
SELECT
E
FROM
EMPLOYEES E
WHERE
E.WORKS != nil
Вызовы методов
В OQL допускается вызов метода объекта с указанием действительных параметров или без
их указания (в зависимости от сигнатуры метода объекта, или класса) в любом месте
запроса, если тип результата вызова метода соответствует типу ожидаемого результата
запроса. Если у метода отсутствуют параметры, то нотация вызова метода в точности
совпадает с нотацией выбора атрибута или перехода по связи. Если у метода имеются
параметры, то их действительные значения задаются через запятую в круглых скобках.
Этот гибкий синтаксис освобождает пользователя от необходимости знать, является ли
свойство хранимым (атрибутом) или вычисляемым (методом). Однако, если в классе (или
интерфейсе) содержатся одноименные атрибут и метод без параметров, то для разрешения
конфликта имен в вызове метода должны содержаться круглые скобки.
Выше уже был вариант запроса, содержащего вызов метода. В модели ODMG допускаются
методы, вырабатывающие результат в виде сложных объектов или коллекций литеральных
значений или объектов. Например, представим себе, что в классе EMP определена операция
HIGHER_PAID , которая для данного объекта-служащего производит множество объектов-служащих
того же отдела с большим размером зарплаты. Тогда возможен следующий запрос.
Пример 14. Найти названия проектов, в которых участвуют сотрудники отдела 632,
получающие зарплату с размером выше среднего.
SELECT DISTINCT
E.HIGHER_PAID.participate_in.PRO_NAME
FROM
EMPLOYEES AS E
WHERE
E.EMP_NO = 632
Здесь мы предполагаем, что между классами EMP и PRO имеется связь “многие-к-одному”
participates_in - participants_of (один сотрудник может принимать участие не более чем в одном проекте,
но в любом проекте может участвовать произвольное число сотрудников).
Полиморфизм
Как уже было отмечено, в объектной модели ODMG поддерживается семантика включения, т.е.
в экстент суперкласса входят объекты экстентов всех его подклассов. Предположим,
например, что мы определили класс PROGRAMMERS как наследника класса EMP через EXTENDS . Пусть для
программистов меняется семантика метода HIGHER_PAID (высокооплачиваемым программистом
считается тот, кто получает более 30000 руб. в месяц). Тогда в классе PROGRAMMERS этот метод
должен быть переопределен (с сохранением сигнатуры).
Понятно, что в соответствии с семантикой включения запрос из прим. 14 должен
распространяться на всех служащих, включая программистов. Но если текущий объект E
является объектом класса PROGRAMMERS , то к нему должен применяться переопределенный
вариант метода HIGHER_PAID. Тем самым, в OQL применятся отложенное связывание объектов и
методов.
Еще одна возможность, связанная с полиморфизмом и поддерживающаяся в OQL, состоит в том,
что пользователь может явно указать конкретный тип подкласса объектов коллекции, а
система будет проверять правильность этого указания во время выполнения запроса.
Предположим, что в классе PROGRAMMERS определен дополнительный атрибут favorite_language , значение
которого характеризуют “любимый” язык программирования каждого программиста. Кроме
того, пусть известно, что в отделе 632 работают только программисты. Тогда возможен
следующий запрос.
Пример 15. Получить названия любимых языков программирования сотрудников отдела
632.
SELECT DISTINCT
((PROGRAMMERS)E).favorite_language
FROM
EMPLOYEES AS E
WHERE
E.EMP_NO = 632
Если во время выполнения запроса будет обнаружено, что среди служащих отдела 632
имеются не только программисты, система зафиксирует ошибочную ситуацию.
Композиция операций
OQL является полностью функциональным языком. Если не нарушается система типов, то
допускается произвольная композируемость операций. Этот подход отличается от подхода
языка SQL , в котором правила композиции операций не являются ортогональными. Наличие
полной ортогональности правил композиции в OQL позволяет не ограничивать мощность
выражений и облегчить общее понимание языка, сохраняя возможность использования SQL-подобного
синтаксиса при формулировке наиболее простых запросов.
Среди операций, которые поддерживаются в OQL и еще не упоминались в этом разделе,
содержатся “множественные” операции union, intersect и except для всех видов
коллекций; операции с кванторами for all и exists; операции сортировки и
группирования (sort и group by); агрегатные операции count, sum, min, max и avg.
Мы не будем подробно обсуждать эти операции, но приведем пример достаточно сложного
запроса, в котором некоторые из операций используются.
Пример 16. Найти название отдела, в котором работают служащие, средняя зарплата
которых меньше средней зарплаты служащих любого другого отдела (для простоты
предположим, что размер средней зарплаты служащих во всех отделах различается).
Будем строить запрос по шагам с использованием конструкции языка OQL define для
вычисления промежуточных результатов.
Шаг 1. Построить множество объектов-служащих, для которых известен номер отдела.
define EMPLOYEES_D () AS
SELECT
E
FROM
EMPLOYEES E
WHERE
E.WORKS IS NOT nil
Шаг 2. Сгруппировать служащих с известными номерами отделов по номерам отделов и
вычислить размер средней зарплаты для каждого отдела.
define DEPT_AVG_SAL () AS
SELECT
DEPT_NO,
AVG_SAL : avg(SELECT
X.E.EMP_SAL
FROM
PARTITION X)
FROM
EMPLOYEES_D () E
GROUP BY
DEPT_NO : E.DEPT_NO
Типом результата этого запросаявляется bag < struct { integer DEPT_NO; decimal AVG_SAL } > . Операция group
by расщепляет множество служащих на разделы (partitions ) в соответствии с критерием
группирования (номеру отдела, в котором работает служащий). В разделе SELECT для каждого
раздела вычисляется размер средней зарплаты сотрудников.
Шаг 3. Отсортировать полученное мультимножество по значениям атрибута AVG _ SAL.
define SORTED_DEPT_AVG_SAL () AS
SELECT
S
FROM
DEPT_AVG_SAL () AS S
ORDER BY
S.AVG_SAL
Типом результата является list < struct { integer DEPT_NO; decimal AVG_SAL } >.
Шаг 4. Выбрать значение атрибута DEPT_NO из элемента списка SORTED_DEPT_AVG_SAL с наименьшим
значением AVG_SAL (этот элемент стоит в списке первым).
FIRST (SORTED_DEPT_AVG_SAL ().DEPT_NO
Если собрать запрос целиком, то мы получим следующую конструкцию:
FIRST (SELECT
DEPT_NO,
AVG_SAL : avg(SELECT
X.E.EMP_SAL
FROM
PARTITION X)
FROM
(SELECT
E
FROM
EMPLOYEES E
WHERE
E.WORKS IS NOT nil) AS E
GROUP BY
DEPT_NO : E.DEPT_NO
ORDER BY
AVG_SAL).DEPT_NO
Достоинства модели объектно-ориентированных баз данных
Объектно-ориентированные базы данных позволяют представлять сложные объекты более
непосредственным образом, нежели реляционные системы. Остановимся на некоторых
имеющихся достижениях в области ООБД. Системы ООБД позволяют пользователям определять
абстракции; облегчают проектирование некоторых связей; устраняют потребность в
определяемых пользователями ключах; поддерживают новый набор предикатов сравнения; в
некоторых случаях устраняют потребность в соединениях; в некоторых ситуациях
обеспечивают более высокую производительность, нежели системы, основанные на
реляционной модели; обеспечивают поддержку версий и длительных транзакций.
Пользовательские абстракции
Объектно-ориентированные базы данных предоставляют возможность определять новые
абстракции и управлять реализацией таких абстракций. Эти новые абстракции могут
соответствовать структурам данных, требуемым в сложных задачах, новым абстрактным
типам данных. Иначе говоря, современные пакеты ООБД дают пользователю возможность
создания нового класса с атрибутами и методами, иметь классы, наследующие атрибуты и
методы от классов-предков, создавать экземпляры класса, каждый из которых обладает
уникальным объектным идентификатором, извлекать эти экземпляры по одному или группами,
а также загружать и выполнять методы. Кроме того, ООБД позволяют определять объекты как
совокупности других объектов, причем для совокупностей допускается несколько уровней
вложенности. Свойства тоже могут иметь сложную структуру и определяться с помощью
конструктора коллекций. Более того, они могут иметь в качестве значений не примитивные
объекты, что дает возможность формировать глубоко вложенные объектные структуры.
Многозначные свойства используются в объектно-ориентированных моделях данных для
выражения сложных структур данных. В реляционной модели это достигается с помощью
дополнительных отношений и соединений.
Всеми перечисленными свойствами в полной мере обладает ENCORE.
Инверсные связи
В объектно-ориентированных базах данных поддерживается средство инверсных связей
для выражения взаимных ссылок между двумя объектами (бинарная связь). Такая система
обеспечивает ссылочную целостность путем установления соответствующей обратной
ссылки сразу же после создания прямой ссылки. Существует даже возможность
автоматического распространения удалений через эти ссылки. Примером пакета ООБД,
обеспечивающего автоматическое поддержание инверсных связей, является ObjectStore.
Первичные ключи
В связи с обязательным условием уникальной идентификации объектов ООБД отпадает
необходимость первичных ключей, эта задача решается автоматически. Это дает и
дополнительные преимущества. Во-первых, идентификатор объекта не может быть
модифицирован приложением. Во-вторых, понятие идентифицируемости объекта влечет
отдельное и согласованное понятие идентичности, независимое от того, каким образом
производится доступ к объекту или как объект моделируется с помощью описательных
данных. Следовательно, два объекта не являются идентичными, если они имеют различные
идентификаторы объектов; при этом объекты могут иметь одинаковые структуры, а все их
свойства — одни и те же значения. В модели РБД, где идентификация объектов
осуществляется через определяемые пользователями ключи, такие объекты считались бы
одним и тем же объектом.
Предикаты сравнения
В РБД сравнение всегда базируется лишь на значениях. В этой модели два кортежа
являются одной сущностью, если все их ключевые атрибуты имеют одинаковые значения.
Однако в модели ООБД были разработаны и определены иные типы сравнения.
- Равенство объектов на основе их идентичности. Два объекта, S1 и S2 равны, если они
являются одним и тем же объектом (т.е. имеют один и тот же идентификатор объекта).
- Равенство объектов на основе значений. Это можно определить в два захода — (a) два
примитивных объекта равны, если имеют одно и то же значение; (b) два не примитивных
объекта равны, если они имеют одинаковое число свойств, и для каждого свойства pi
объекта S1 существует свойство pj объекта S2, равное ему по значению.
- Равенство свойств на основе значений.
- Равенство свойств на основе их идентичности.
Соединения
Возможность навигации по структурам объектов и проистекающие из этого путевые
выражения в терминах атрибутов объектов дают нам возможность по-новому взглянуть на
проблему соединений в ООБД. Реляционное соединение — это механизм, сопоставляющий два
отношения на основе значений соответствующих пар атрибутов в этих отношениях.
Поскольку в ООБД два класса могут иметь соответствующие пары атрибутов, в этой модели
все еще может сохраняться необходимость в реляционном соединении (или явном
соединении). Например, допустим, у нас имеются классы Student и School, причем в каждом из этих
классов имеются атрибуты Name и Age. Хотя домены атрибутов Name и Age класса School могут не
совпадать с доменами атрибутов Name и Age класса Student, мы можем захотеть связать эти классы
на основе значений этих атрибутов (скажем, найти всех учащихся, чей возраст меньше
возраста школы, которую посещает данный учащийся).
Но, как уже отмечалось, поддержка путевых выражений может существенно сократить
потребность в соединении классов по сравнению с ситуацией в РБД. Имеются даже ситуации,
в которых потребность в реляционном объединении может быть полностью устранена.
Например, когда доменом атрибута класса A является класс B, выборка идентификаторов
объектов некоторого класса, которые хранятся как значения атрибута другого класса,
устраняет потребность в неявном соединении объектов.
Таким образом, в объектно-ориентированных базах данных неявные соединения,
порождаемые иерархической вложенностью объектов, отличаются от явных объединений.
Последние напоминают реляционные соединения: два объекта сравниваются явным образом
по значениям атрибутов или объектных идентификаторов. Более того, все явные соединения
(основанные на сравнении значений или идентификаторов) не могут быть выражены на
реляционном языке запросов, поскольку в РБД любой предикат может содержать только
атомарные атрибуты.
Производительность
Современные ООБД не являются полностью оперившимися системами баз данных по
сравнению с современными РБД, ООБД обладают несколькими особенностями,
обеспечивающими их выигрыш в производительности.
- В ООБД значение атрибута объекта X, доменом которого является другой объект Y, — это
идентификатор объекта Y. Следовательно, если приложение уже извлекло объект X и
теперь хотело бы извлечь объект Y, то СУБД может извлечь объект Y, отыскав его
идентификатор. Если этот идентификатор представляет собой физический адрес объекта,
то данный объект может быть извлечен непосредственно; если же идентификатор
является логическим адресом, то объект путем нахождения соответствующего элемента
хэш-таблицы (в предположении, что в системе поддерживается хэш-таблица, отображающая
идентификатор объекта в физический адрес). В РБД это могло бы не получиться так
просто, поскольку в РБД не поддерживаются идентификаторы объектов.
- Вторая особенность ООБД, обеспечивающая выигрыш в производительности, состоит в
том, что в большинстве ООБД при загрузке объекта в память хранимые в этом объекте
идентификаторы объектов преобразуются в указатели по памяти. Поскольку в РБД не
хранятся идентификаторы объектов, в них невозможно сохранять указатели по памяти на
другие кортежи. Отсутствие возможности навигации по объектам, содержащимся в памяти,
является принципиальным свойством РБД, и вытекающее из этого снижение
производительности не может быть компенсировано простым увеличением объема
буферной памяти. Так что при выполнении приложений, которые предполагают
многократную навигацию по загруженным в память связанным объектам, ООБД могут
существенно превзойти РБД по производительности.
- Кроме того, даже если ООБД не проиндексированы, может оказаться удобным выполнять
произвольные запросы, соответствующие структуре объектов, путем последовательного
сканирования, т.е. использовать ссылочные пути между объектами. Когда запрос
формулируется в направлении, не поддерживаемом ссылками, этот запрос будет
обрабатываться путем последовательного сканирования. Однако запросы, формулируемые
на основании таких связей объектов, которые не моделируются напрямую с помощью
ссылок, выполняются неэффективно.
Версии и длительные транзакции
В РБД не поддерживаются ни работа с версиями, ни длительные транзакции. Такая
поддержка имеется в некоторых ООБД, хотя и с ограниченными возможностями.
Объектная алгебра
Объектная алгебра не столь подробно разработана и не является столь же зрелой, как
реляционная алгебра. Но как бы то ни было, такая алгебра существует, и в ней
определяются пять фундаментальных операций, сохраняющих объекты: union, difference, select,
generate и map. На основе этих фундаментальных операций могут быть определены другие
операции, например, intersection. В то время как операции union, difference и map
производят, главным образом, отображение «один к одному», операции select и generate
производят отображение «один ко многим». Сохранение объектов означает, что
алгебраические операции возвращают объекты, принадлежащие к ранее определенным
классам базы данных, и не создают новых объектов. Оператор union возвращает объекты,
содержащиеся во множестве P или во множестве Q, или в обоих множествах. Оператор difference
возвращает набор объектов, принадлежащих множеству P, но не множеству Q. select возвращает
подмножество введенного множества. generate генерирует объекты из тех, что принадлежат
входному множеству. map возвращает множество объектов, образующихся в результате
каждого применения последовательности методов.
Недостатки модели объектно-ориентированных баз данных
В объектно-ориентированных базах данных отсутствуют базовые средства, к которым
пользователи систем баз данных привыкли и поэтому ожидают видеть. Среди прочего, можно
отметить: отсутствие интероперабельности между РБД и ООБД; минимальную оптимизацию
запросов; отсутствие стандартной алгебры запросов; отсутствие средств обеспечения
запросов; отсутствие поддержки представлений; проблемы с безопасностью; отсутствие
поддержки динамических изменений определений классов; ограниченная поддержка
ограничений целостности; ограниченные возможности настройки производительности;
недостаточная поддержка сложных объектов; ограниченная интеграция с существующими
объектно-ориентированными системами программирования; ограниченный выигрыш в
производительности.
Интероперабельность
Чтобы ООБД смогли оказать значительное влияние на рынок баз данных, необходимо
выполнить ряд условий.
- Превратить ООБД в полностью оперившиеся системы баз данных, обладающих достаточной
совместимостью с РБД. Требуется некий путь миграции, чтобы обеспечить
сосуществование существующих ныне и новых продуктов, а также плавный переход от
первых ко вторым.
- Предложить средства разработки приложений и средства доступа к объектно-ориентированным
базам данных.
- Унифицировать архитектуры РБД и ООБД.
- Унифицировать модели данных РБД и ООБД.
Оптимизация запросов
Одной из самых значительных проблем в ООБД является оптимизация декларативных
запросов. Оптимизацию запросов к ООБД затрудняет дополнительная сложность самой
объектно-ориентированой модели данных. Эта дополнительная сложность обусловлена
рядом факторов.
- Возможность определения пользователями новых типов и классов с помощью
наследования и облегчает, и осложняет оптимизацию запросов. Примером, в котором эта
возможность помогает оптимизации, может служить запрос, включающий пересечение
множеств Employees («сотрудники») и Supervisors («инспекторы»). Если Employee является суперклассом
класса Supervisor, то оптимизатор может исходить из того, что Supervisors является собственным
подмножеством Employees и упростить процедуру пересечения множеств. Пример, в котором
дополнительные типы данных ограничивают возможности оптимизации, может служить
объединение множеств Students и Employees; суперклассом для обоих классов является класс Person.
Если бы мы захотели найти всех инспекторов студентов и служащих, мы бы сначала
произвели объединение, а применили бы supervisor().
- Запросы могут базироваться на операциях над коллекциями, но виды оптимизации,
затрагивающие множества (или мультимножества, или списки и т.п.), нужно сочетать с
оптимизацией над типами объектов, содержащихся в этих множествах. Объектно-ориентированный
оптимизатор запросов должен быть в состоянии применять процедуры оптимизации,
характерные для данных типов, а также процедуры оптимизации, учитывающие связи между
объектами разных типов.
- Сложность обработки запросов в ООБД усугубляется наличием сложных объектов,
методов и инкапсуляции. Сложные объекты порождают путевые выражения, которые
усложняют обработку запросов. Создание индексов для путевых выражений, особенно при
наличии в выражениях произвольных методов, усложняет обработку запросов. Проблема
еще более осложняется, если методы обладают побочными эффектами. Еще одна проблема,
связанная с путевыми выражениями, состоит в том, что они навязывают порядок вызовов
методов путевого выражения, и этот порядок может быть весьма неэффективным. Например,
путевое выражение Orders.part.name лучше вычислять справа налево, если имеется много
заказов (Orders) и мало деталей (Parts), но если деталей много, а заказов мало — выражение
лучше вычислять слева направо. Кроме того, иногда путевые выражения более эффективно
обрабатываются с использованием Join. Рассмотрим, например, запрос с путевым
выражением s.comp.name, где s принадлежит множеству Students (студенты). Могло бы оказаться
более эффективно (если число компаний, comp, невелико) сначала вычислить название (Name)
для каждой компании (Company) и сохранить результат в кортеже. Тогда вычисление
выражения от студента до названия компании включало бы соединение множества Students с
множеством кортежей путем сопоставления свойства comp класса student со значением
атрибута Company некоторого кортежа.
- В языках запросов к ООБД поддерживается использование вложенных структур, которые
опять-таки могут существенно усложнить процесс оптимизации, поскольку превращают
его из локальной проблемы в проблему глобальную, поскольку требуется глобальное
знание всего выражения запроса.
- Когда объекты обладают идентифицируемостью, возникает вопрос, а что же понимается
под равенством двух объектов. Этот вопрос переносится в язык, где операции сравнения
по равенству используются в предикатах, и где необходимо принимать решение о
создании новых объектов при выполнении запроса. Оптимизатор объектно-ориентированных
моделей должен быть в состоянии решать проблемы, связанные с созданием новых
объектов и с альтернативными определениями равенства.
Перечисленные проблемы указывают на то, что оптимизация объектно-ориентированных
запросов является чрезвычайно сложной задачей, и эта область все еще находится в
стадии исследований. В сегодняшних системах объектно-ориентированных баз данных
предлагаются довольно простые стратегии оптимизации. Более пристального внимания
требует также проблема оптимизации соединений.
Алгебра запросов
Еще один серьезный недостаток ООБД состоит в отсутствии стандартов алгебры запросов.
Это обстоятельство тоже затрудняет оптимизацию запросов. Для ООБД было предложено
несколько разных формальных языков запросов, основанных на алгебрах и исчислениях. Эти
алгебры и исчисления отличаются в нескольких отношениях, и по выразительности, и по
поддержке оптимизирующих правил перезаписи. Почти все эти алгебры базируются на
переменных, т.е. используют переменные для хранения промежуточных результатов.
Исключением является KOLA, чисто функциональный продукт, где переменные не используются.
В РБД существует близкое соответствие между алгебраическими операциями и
низкоуровневыми примитивами физической системы. Это строгое соответствие достигается
за счет отображений между отношениями и файлами, а также между кортежами и записями.
Однако в ООБД нет аналогичного интуитивного соответствия между операциями объектной
алгебры и примитивами физических систем. При всяком обсуждении генерации плана
выполнения тоже необходимо, прежде всего, определить низкоуровневые примитивы
манипулирования объектами.
Средства обеспечения запросов
В большинстве ООБД не хватает средств обеспечения запросов. В тех же немногих
системах, где имеются достаточные соответствующие средства, язык запросов не
совместим с ANSI SQL. Среди этих средств обеспечения запросов нет вложенных подзапросов,
запросов с множествами (union, intersection, difference), агрегатных функций и GROUP BY, соединения
нескольких классов — возможностей, полностью поддерживаемых в РБД.
Представления
В ООБД не поддерживаются представления. Хотя по этому поводу было выдвинуто
несколько предложений, не удалось придти к единому мнению относительно того, как
механизм представлений должен функционировать в ООБД. Разработка объектно-ориентированного
механизма представлений осложняется такими свойствами модели, как идентифицируемость
объектов. Что такое идентификатор объекта в представлении? С другой стороны,
высказывается точка зрения, согласно которой возможность инкапсуляции данных и
наследования позволяет обойтись без явных определений представлений.
Безопасность
В некоторых системах ООБД пользователи должны явным образом устанавливать и снимать
блокировки. Системы РБД автоматически устанавливают и снимают блокировки при
обработке пользовательских запросов и операторов обновления.
Динамическое изменение определений классов
В дополнение к тому, что для ООБД до сих пор не разработана единая стандартная модель
данных, в большинстве ООБД не допускаются динамические изменения схемы баз данных,
таких как добавление к классу нового атрибута или метода, добавление к классу нового
суперкласса, удаление суперкласса класса, добавление нового класса и удаление класса.
РБД позволяют пользователю динамически изменять схему базы данных с помощью команды
ALTER; к отношению может быть добавлен новый столбец, отношение может быть удалено, а в
некоторых случаях имеется возможность удаления столбца из отношения.
В большинстве ООБД отсутствует и автоматическое управление расширениями классов.
Если требуется расширение класса, пользователь должен определить для него коллекцию и
следить за тем, чтобы в ней своевременно фиксировались все вставки и удаления.
Ограничения целостности
Отсутствуют механизмы объявления ключевых свойств атрибутов (например, атрибут
класса не может быть объявлен первичным ключом класса), или ограничений уникальности,
явных ограничений целостности, а также пред- и постусловий методов. Хотя все это можно
сделать с использованием методов, явные ограничения были бы удобнее для пользователей,
порождали бы меньше ошибок и были бы более доступными для проверки и модификации.
Настройка производительности
В большинстве ООБД имеются лишь ограниченные средства параметризованной настройки
производительности. В РБД инсталляторам предоставляется возможность настраивать
производительность системы путем задания большого числа параметров, устанавливаемых
системным администратором. Эти параметры включают число буферов памяти, объем
свободного пространства, резервируемого в странице данных для будущей вставки данных
и т.д.
Поддержка сложных объектов
Полная функциональность сложных объектов все еще не поддерживается. Можно
осуществлять навигацию по ссылкам и кодировать операции с применением этих ссылок, но
отсутствуют предопределенные родовые операции, в которых используются различные виды
семантики ссылок. Считается, что все ссылки указывают на независимые объекты, а
семантика особых связей внутри сложных объектов скрыта в операциях, предоставляемых
пользователями.
Интеграция с объектно-ориентированными системами программирования
Трудно переписывать объектно-ориентированные программы для управления стабильными
данными. Здесь возникает ряд проблем: конфликты по именам; необходимость переделывать
иерархии классов; склонность ООБД к перегрузке системных операций.
Производительность
Если бы всем приложениям баз данных требовались только поиск объектов базы данных
через идентификаторы объектов и быстрая работа с объектами в основной памяти с
использованием указателей, то ООБД действительно превосходили бы РБД по
производительности на два-три порядка. Однако для большинства приложений, которым
требуется доступ к объектам через идентификаторы, нужны также и возможности доступа к
базе данных и ее обновления, обеспечиваемые в РБД. В число этих возможностей входят
массовая загрузка базы данных; создание, обновление и удаление индивидуальных
объектов (по одному); извлечение из класса одного или более объектов, удовлетворяющих
определенным условиям поиска; соединение нескольких классов; фиксация транзакций и т.д.
При выполнении таких приложений ООБД не имеют никаких преимуществ в
производительности по сравнению с РБД.
В числе средств, пока что не поддерживаемых в ООБД, также можно назвать триггеры,
средства управления метаданными, а также ограничения целостности, такие как UNIQUE и NULL.
Выводы по сравнению достоинств и недостатков
Из-за указанных слабостей ООБД не смогли оправдать возлагавшихся на них ожиданий:
обеспечить все важные средства, желательные для целевых приложений. Применительно к
большинству современных систем термин «ООБД» используется неправильно. Почти все
современные ООБД — не столько системы баз данных, сколько системы стабильного
хранения данных для некоторого объектно-ориентированного языка программирования. Так
что, хотя объектно-ориентированная модель данных во многих отношениях богаче
реляционной модели, объектно-ориентированная модель еще не вполне вступила в период
зрелости. На сегодняшний день недостатков в системах ООБД явно больше, чем достоинств.
Системы управления объектно-ориентированными базами данных
Domino
По результатам опроса IDC были указаны в порядке убывания интенсивности использования
следующие технологии, которые и составляют суть «ПО для совместной работы»:
- Электронная почта.
- Средства распространения и совместного использования информации.
- Управление документами.
- Возможности выполнения специализированных приложений.
- Средства календарного планирования и составления расписаний.
- Средства управления корпоративными знаниями.
- Управление потоками работ (workflow).
- Средства поддержки приложений «дискуссионного» типа.
- Мгновенная пересылка сообщений (chat).
- Конференции в реальном времени.
Lotus Domino и Notes сами по себе, а также в сочетании с другими продуктами семейства Domino
включают все перечисленные выше технологии. И все же если говорить о ключевых
технологиях, важных с точки зрения понимания архитектуры продукта и возможностей его
применения, то можно выделить следующие:
- Документоориентированная база данных.
- Средства разработки приложений.
- Система электронной почты.
- Система реплицирования (тиражирования) документов, информации и приложений.
- Средства защиты информации и разграничения доступа.
- Средства календарного планирования и составления расписаний.
- Web-технологии и технологии Internet/Intranet.
- Средства интеграции с реляционными базами данных, системами управления ресурсами
предприятий (ERP) и транзакционными системами.
Многие из этих технологий, взятые в отдельности, были достаточно хорошо известны и до
появления Notes. Но, объединенные вместе в рамках единой системы, они дали совершенно
новое качество, которое позволяет утверждать: в настоящее время на рынке нет аналога
данному программному продукту.
Domino/Notes — это клиент-серверная технология, где в качестве сервера выступает Lotus Domino, а
в качестве клиентской части — Lotus Notes. Однако сразу же следует отметить уникальность
сервера Domino, которая состоит в том, что это еще и Web-сервер и почтовый сервер,
поддерживающий стандарты Internet, поэтому в качестве клиентской части для работы с
приложениями Domino и электронной почтой могут использоваться Web-браузеры и другие
почтовые клиенты Internet. За счет поддержки промышленных стандартов, таких, в частности,
как ODMA, ActiveX, OLE и ряда других, для доступа и сохранения данных на сервере Domino с той или
иной степенью полноты в качестве клиентов могут использоваться популярные офисные
пакеты, мобильные телефоны, персональные цифровые помощники типа PalmPilot, пейджеры и т.д.
Документоориентированность
Сердцем Domino и Notes является хранилище объектов, известное как NSF (Notes Storage File), в котором и
хранятся данные.
Базы данных Domino и Notes отличаются от реляционных СУБД, с которыми многие привыкли
работать. В реляционных СУБД данные описываются с помощью таблиц, жестко задающих
формат данных.
Основой единицей хранения информации в базе данных Lotus Domino/Notes является отдельный
документ. Структура документа Notes определяется формой, содержащей в себе набор полей
различных типов. Например, документ, относящийся к обслуживанию клиентов, может
содержать в себе дату, имя клиента, идентификационный номер клиента, имя оператора,
текстовое поле для описания запроса клиента, а также поле статуса запроса. Notes
использует индексированные представления для отображения списков документов,
навигаторы и полнотекстовые индексы для поиска документов, а также агенты для
автоматизации определенных процессов в базе.
База данных Notes может хранить любые типы данных — от простого текста, чисел, времени и
даты до форматированного текста, графических образов, звука, видео и произвольных
данных, которые могут храниться в виде присоединенных объектов в своем родном формате.
Для того чтобы гарантировать адекватную масштабируемость для любых целей, размер
хранилища объектов Domino ограничен только доступными физическим ресурсами. Это
хранилище может распространяться за границы физических систем хранения.
Высокооптимизированный формат минимизирует использование операций ввода-вывода, что
уменьшает число обращений к дискам и делает эти обращения более эффективными.
В целях обеспечения высочайшей надежности и защиты от потери данных хранилище
объектов Domino использует лучшие алгоритмы журналирования или протоколирования
транзакций. Операции с базами данных записываются последовательно, уменьшая
активность ввода-вывода одновременно с оптимизацией целостности данных и ускорением
перезапуска сервера.
Базы данных Domino/Notes поддерживаются целым набором сервисов, которые берут на себя
выполнение большого количества операций нижнего уровня. Например, отдельный сервис
отвечает за создание и обновление индексов, сервис репликации отвечает за поддержание
копий баз данных на разных серверах и клиентских машинах в синхронном по отношению
друг к другу состоянии, сервис маршрутизации отвечает за доставку почтовых сообщений и
т.д. Эти сервисы выполняются на сервере Domino, некоторые из них — также на клиенте Notes.
Разработчики приложений для Domino не должны думать об этих задачах нижнего уровня, а
могут полагаться на сервисы Domino, которые выполнят эту трудоемкую, полную мелких
деталей, черновую работу.
Базы данных Notes, как правило, располагаются на серверах Domino, однако могут находиться и
на клиентских машинах с Notes, что является очень важным с точки зрения поддержки работы
пользователей в режиме off-line и мобильных пользователей. Пользователи получают доступ к
данным на сервере через сеть, либо через модем, либо работая с данными локально с
помощью клиента Notes. Однако, как уже отмечалось, в качестве клиента для работы с данными
и приложениями на сервере Domino могут использоваться Web-браузеры, почтовые клиенты Internet и
т.д.
Пользователи имеют возможность просмотра списков документов, хранящихся в базе
данных Domino/Notes, которые также называются представлениями, видами или взглядами (view).
Когда пользователь Notes открывает вид, то названия полей выводятся как заголовки
столбцов данных. Если, например, пользователь желает просмотреть документы по дате, то
Notes, отсортировав их по значениям в этом поле, открывает вид, самый левый столбец
которого содержит дату, а прочая информация из полей (номер клиента, название политики
и т.п.) выводится в столбцах справа от основного.
Репликация
По сути, системой репликации решаются две основные задачи:
- Поддержка территориально-распределенной работы (синхронизация данных и приложений).
- Поддержка работы мобильных пользователей.
Электронная почта и передача сообщений
Система может быть охарактеризована словами: надежная, масштабируемая, защищенная и
управляемая. В мире есть организации, в которых более 100 и даже 200 тысяч сотрудников
объединены системой передачи сообщений Domino и Notes. Это означает, что, выбрав эту
технологию, вы не натолкнетесь на такие технологические ограничения, когда все
работает хорошо при десятках или нескольких сотнях пользователей, но при дальнейшем
расширении инфраструктуры начинаются непреодолимые проблемы. Что касается
защищенности, то Domino предлагает самую мощную из возможных систему защиты для почты в
Internet, применяемую для подписываемых и шифруемых сообщений, за счет бесшовной
интеграции инфраструктуры публичных ключей (Public Key Infrastructure, PKI) и сертификатов X.509 V3.
Средства разработки
Платформа Notes включает в себя интегрированную среду разработки, предоставляющую
мощные средства разработчикам с самым различным опытом. Пользователи, не обладающие
опытом программирования, могут быстро построить и создать простые, но полезные
приложения Notes, тогда как профессиональные разработчики имеют возможность создавать
мощные приложения с использованием встроенных в Notes средств программирования.
Средства разработки приложений интегрированы в Domino Designer, продукте, который является
надежной, интуитивно понятной средой, обеспечивающей возможности использования
стандартных средств и языков разработки Web-приложений и доступ к другим корпоративным
системам.
Защита информации
Стандартом de facto в отрасли для доступа к каталогам X.500 является сертификат X.509,
основанный на технологии шифрования RSA с открытым ключом. Инфраструктура публичных
ключей Domino и Notes (PKI — Public Key Infrastructure) имеет самое большое число инсталляций из
существующих в мире. Domino может также выступать в качестве средства по созданию
сертификатов (CA — Certificate Authority), выпуская сертификаты X.509 не только для Notes, но также и для
других клиентов, таких как Web-браузеры.
Аутентификация с использованием публичных ключей исключает необходимость передачи
паролей по сети. Публичные ключи, используемые вместе с частными ключами пользователей,
делают возможным создание цифровых подписей и полное шифрование документов и почтовых
сообщений.
Инфраструктура Domino и Notes обеспечивают четыре уровня безопасности:
- Аутентификация, которая основана на сертификатах и обеспечивает надежную проверку
того, что пользователи, подключающиеся к сетевым ресурсам Domino, являются теми, за кого
они себя выдают.
- Цифровые подписи, благодаря которым серверы Domino и клиенты Notes делают аутентификацию
отправителя, что гарантирует, что информация, например, не подверглась изменениям в
процессе передачи.
- Контроль доступа, который определяет, кто может использовать некий ресурс (сервер,
базу данных, документ) и то, что он может с этим ресурсом делать в зависимости от
присутствия имени пользователя в соответствующем списке контроля доступа (Access Control
List) и предоставленных прав. Списки контроля доступа контролируют доступ к данным на
уровне сервера, базы данных, и отдельных документов. Списки контроля доступа имеют
семь уровней возможностей по работе с информацией по мере увеличения: «нет доступа»,
депозиторы, читатели, авторы, редакторы, дизайнеры, менеджеры. В дополнение отдельные
поля могут быть зашифрованы. Пользователям Internet может быть предоставлен анонимный
доступ, доступ по паролю, любо доступ на основе предъявления сертификата так, как это
определено протоколом Internet Secure Sockets Layer (SSL).
- Шифрование, обеспечивающее безопасную связь между отдельными пользователями.
Средства планирования
С помощью встроенного в клиентское место Notes календаря пользователи могут назначать
встречи, планировать совещания, просматривать любой временной промежуток месяцев,
недель или дней, выбирать даты для просмотра и многое другое.
Internet
Domino — это Web-сервер, поддерживающий стандарты HTTP и HTTPS. Так же как любой другой Web-сервер
он может взять HTML-файл и предоставить его Web-браузеру. То, что уникально отличает Domino от
других Web-серверов — это возможность помимо прочего «на лету» конвертировать
документы Notes в формат HTML и предоставлять, таким образом, абсолютно актуальную
информацию из баз Notes пользователю, который ее запрашивает с помощью браузера. Таким
образом, информация для Вашего Web-узла будет храниться не в виде файлов HTML в файловой
системе, а в виде документов базы данных Domino как защищенного надежного хранилища
объектов, поддерживающего все необходимые ссылки.
Средства интеграции
Сервер Domino обладает возможностями по обмену данными с другими информационными
системами, такими как реляционные СУБД. В сочетании с богатыми возможностями Notes можно
создать передовой интерфейс доступа к корпоративным данным как через Notes, так и через
Web, объединяющий практически все источники информации.
GemStone
Как отмечалось выше, ООСУБД GemStone была одной из первых коммерчески доступных ООСУБД.
Система была разработана компанией Servio-Logic совместно с OGI. В исходном варианте системы
разработчики GemStone опирались на язык Smalltalk. Хотя в первых выпусках системы ее основной
язык назывался Opal, сразу было видно, что в действительности этого всего лишь Smalltalk с
поддержкой стабильного хранения объектов, и вскоре название языка было заменено на
GemStone Smalltalk. Впоследствии в GemStone была обеспечена поддержка языков C и C++, но во все времена
базовым языком оставался Smalltalk, а все остальные интерфейсы строились поверх базового. И
серверная, и клиентская части системы могут работать под управлением всех основных
ветвей ОС UNIX и всех развитых вариантов Windows . В настоящее время продукт поддерживается,
развивается и распространяется компанией GemStone Systems Inc. (www.gemstone.com).
Система основана на трехзвенной архитектуре клиент-сервер, в которой прикладная
обработка данных производится на среднем уровне между процессом взаимодействия с
пользователем и процессом, поддерживающим хранилище данных. Важность этого подхода
состоит в том, что, если в приложении используется много данных, то код приложения
целесообразно расположить на стороне хранилища данных, а если в приложении
производится много изменений над небольшим объемом данных, то имеет смысл разместить
код приложения на стороне пользователя. Тем самым, архитектура позволяет уменьшить
объем сетевого трафика без перегрузки сервера, что повышает скорость обработки данных.
Для управления мультидоступом используется механизм транзакций. Механизм основан на
так называемом оптимистическом подходе, при котором каждая сессия работает с
собственной локальной копией хранилища объектов, и слияние произведенных в сессиях
изменений хранилища происходит при завершении транзакции. Если при завершении
транзакции обнаруживается, что произведенные в ней изменения конфликтуют с
изменениями других ранее зафиксированных транзакций, то фиксация транзакции не
производится, транзакция не завершается, и решение проблемы возлагается на
пользователя. Автоматическая блокировка объектов не производится, но пользователь
может явно запросить блокировку, что повышает шансы на успешную фиксацию транзакции.
Для обеспечения безопасности данных поддерживается механизм авторизации доступа на
уровне владельца объекта и его группы пользователей, так что может быть ограничен
доступ к некоторым объектам или некоторым методам объектов. К каждому объекту
приписывается авторизационный объект, содержащий данные о том, какие пользователи и в
каком режиме (чтения или изменения) имеют доступ к объекту.
Для восстановления базы данных после сбоев аппаратуры используются механизмы
репликации, резервного копирования и журнализации. Любой авторизованный пользователь
может запросить выполнения полного или частичного копирования. Восстановление базы
данных после сбоя системы или дисковых устройств начинается с использования последней
по времени резервной копии. После этого при помощи данных, сохраненных в журнальных
файлах, хранилище объектов приводится к состоянию, соответствующему последней до
момента сбоя зафиксированной транзакции. Авторизованные пользователи могут также
запросить поддержку реплицирования областей хранилища данных.
В системе поддерживается целостность по ссылкам между всеми объектами, поскольку все
ссылки основываются на использовании объектных идентификаторов, и объекты, для
которых существуют ссылки от других объектов, не могут быть удалены. Для повышения
скорости доступа к часто используемым коллекциям обеспечивается средство построения
индексов.
Объекты делаются стабильными (т.е. сохраняются в базе данных) путем использования
своего рода стабильного корня, называемого коннектором. Все объекты, прямо или
косвенно достижимые по объектным ссылкам от коннектора, являются стабильными. В GemStone
каждого класса, в котором существует хотя бы один стабильный объект, поддерживается
эквивалентная серверная версия класса. Другими словами, один вариант класса служит
классом в контексте программирования, а другой – в контексте базы данных. Такие пары
поддерживаются автоматически: если создается класс в смысле Smalltalk , и некоторый объект
этого класса становится стабильным, то автоматически создается серверный класс этого
объекта (класс в смысле GemStone ). Создание коннектора приводит к появлению экземпляра
класса GemStone , эквивалентного классу объекта, который должен быть сделан стабильным.
Аналогично, любой объект, достижимый от коннектора, автоматически становится
стабильным.
В GemStone поддерживается динамическая сборка мусора (garbage collection). Процесс-“мусорщик”
автоматически освобождает память, занимаемую объектами, на которые отсутствуют ссылки.
В среде GemStone можно использовать различные реализации Smaltalk , а также языки C и C++. Классы
и объекты можно создавать с использованием любого из этих языков, и объекты, созданные
на одном языке можно использовать в приложениях, написанных на любом другом языке.
Реализация языка C представляет собой набор функций и набор компонентов, преобразующих
объекты GemStone в указатели и литералы C и наоборот. Реализация C++ включает препроцессор в
чистый С и библиотеку классов.
Подключения к реляционным системам (например, Oracle или IBM DB 2) производятся через шлюзы.
Для синхронизации состояния локальной (управляемой GemStone ) и внешних копий данных
обеспечивается автоматическая модификация данных. В зависимости среды и требований к
уровню синхронизованности эти обновления выполняются немедленно или же в пакетном
режиме.
GemStone можно также использовать для управления данными, соответствующими стандартам OLE
и CORBA. Для работы с данными в реляционном стиле поддерживаются стандарты SQL и ODBC.
ITASCA
Распределенная ООСУБД ITASCA основана на результатах проекта Orion, выполнявшегося в MCC .
Разработка серии из трех прототипов завершилась выпуском системы, основанной на
архитектуре “много клиентов - много серверов”. Система была доведена до уровня
коммерческого продукта начинающей техасской компанией, которая в 1995 г. была
приобретена компанией IBEX Corp. (www.ibex.ch).
В распределенной архитектуре ITASCA частные и совместно используемые базы данных
разнесены по узлам локальной UNIX-ориентированной сети. Каждой значение данных хранится
в одном узле, но централизованное управление отсутствует; все серверы автономны. На
каждом сервере поддерживаются кэш страниц и кэш объектов, и каждый сервер множество
клиентов с обеспечением мультидоступа на основе блокировок. На клиентах
поддерживается только кэш объектов.
Для управления мультидоступом в ITASCA используется двухфазный протокол
синхронизационных блокировок с сериализацией транзакций и обнаружением тупиков.
Также поддерживаются долгие транзакции на основе перемещения объекта из совместно
используемой базы данных в частную базу данных (check-out ). Для обеспечения совместной
работы допускается участие нескольких пользователей в одной долгой транзакции.
Для всей распределенной базы данных поддерживается единая схема с использование
подсхем для частных фрагментов базы данных. Модель данных включает следующие аспекты:
- множественное наследование;
- представление классов в виде объектов;
- наличие свойств и операций классов;
- наличие свойств и операций классов;
- поддержка ограничений целостности;
- возможность перегрузки операций.
В любое время могут добавляться новые данные, классы, свойства и операции. Для
обеспечения контроля над распространением таких операций как удаление объекта
имеется возможность определения составных объектов. Для поддержки мультимедийных
приложений имеется возможность использования линейных массивных объектов, которые
предназначены прежде всего для хранения последовательных данных, таких как текст или
аудиоданные. В пространственных массивных объектах имеются два измерения, и они
подходят, например, для хранения изображений.
Восстановление базы данных после сбоев производится на основе журнала,
предназначенного для аннулирования результата выполненных операций (undo log). Это
позволяет в процессе восстановления устранить эффект всех транзакций, не
завершившихся к моменту сбоя. Фиксация транзакции заключается в том, что на сервере все
объекты, измененные данной транзакцией, перемещаются из буфера объектов в буфер
страниц.
Поддерживается механизм индексирования, основанный на использовании техники B+-деревьев.
Можно создавать индексы для одного класса и одного свойства или для нескольких свойств
нескольких классов.
Имеется возможность создания классов, поддерживающих оповещение. Имеются две формы
оповещения – пассивная и активная. Пассивное оповещение состоит в том, что сохраняется
информация о модификации или удалении экземпляров класса. Приложение может обратиться
классу с запросом данных о таких событиях. Активное оповещение приводит к вызову
некоторой операции при выполнении операций модификации, удаления, создания версии,
перемещения объекта из общей базы данных в частную базу данных (check -out ) или наоборот
(check-in ). По умолчанию выполнение операции оповещения приводит к отправке электронной
почты привилегированному пользователю (администратору системы), но допускается замена
поведения этой операции.
Допускается создание временной, рабочей или “выпускной” версии объекта. Для
динамического или статического связывания разных версий поддерживается иерархия
происхождения версий. При использовании динамического связывания версий иерархия
автоматически модифицируется при создании новых версий.
Безопасность данных обеспечивается на основе механизма авторизации доступа, в
котором конкретная привилегия (доступ по чтению, доступ по записи или создание)
предоставляется роли, за которой может стоять один пользователь или группа
пользователей. Привилегии могут быть подсоединены к базам данных, классам, экстентам,
объектам, операциям и свойствам. Имеется авторизация по умолчанию, которая
подразумевается для любой роли и может быть дополнена явной авторизацией,
положительной (с добавлением привилегий) или отрицательной (с изъятием привилегии).
При использовании C++ стабильность достигается путем доступа к библиотеке классов,
поддерживающих стабильность. В CLOS (Common Lisp Object System) обеспечивается метакласс
стабильности. Стабильные объекты должны быть экземплярами классов, являющихся
экземплярами этого метакласса. Кроме того, можно указать, что некоторые свойства
стабильного класса являются недолговечными.
В ITASCA поддерживаются C , C++, Smalltalk, CLOS. Акцент делается на возможности динамического
изменения схемы без остановки действия системы и без потребности в массовой повторной
компиляции и редактирования связей. Доступ к программам на каждом из языков
производится через функциональный API. В случае использования C++ автоматически
создается файл заголовков, который сливается с исходными файлами программного кода
при генерации приложения.
Собственный механизм запросов ITASCA позволяет запрашивать данные в частной базе
данных, общей базе данных или сразу в обеих базах данных. Для повышения
производительности применяются оптимизация запросов и методы распараллеливания.
ObjectStore
Компания Object Design была основана в 1988 г. с экстренной целью разработать и вывести на
рынок ООСУБД, которую стали называть ObjectStore. В конце 90-х у Object Design установились тесные
партнерские отношения с IBM, что позволило привлечь к ObjectStore тысячи разработчиков
приложений. На основе технологии ObjectStore компанией был разработана одна из первых
коммерческих СУБД – Excelon, ориентированная на управление XML-данными. С начала 2003 г.
компания является подразделением компании Progress Software (www.objectstore.net).
ООСУБД ObjectStore основана на архитектуре клиент-сервер, в которой каждый сервер отвечает
за регулирование доступа к хранилищу объектов и управляет журнализацией обновлений,
блокировками, установкой контрольных точек, разрешением конфликтов по данным,
резервированием данных и восстановлением базы данных после сбоев. Каждый сервер
поддерживает множество клиентов. В клиентском процессе используется представление
данных более высокого уровня, и клиентская часть ObjectStore отвечает за управление
коллекциями, выполнение запросов и управление транзакциями.
Серверная часть спроектирована в расчете на использование механизма отображения
виртуальной памяти, которая распространяется на всю сеть и может охватывать несколько
серверов. Извлекаемые из базы данных объекты могут объединяться в пакеты для передачи
по сети, что позволяет снизить объем сетевого трафика. Для сокращения времени доступа в
серверах используется техника кластеризации. На каждой клиентской части имеется
локальный кэш, в котором сохраняются используемые объекты. Когда объект перемещается в
адресное пространство клиента, ссылки на него перерабатываются таким образом, что для
каждого к объекту доступа достаточно одной команды компьютера.
Управление мультидоступом основано на использовании прозрачного для пользователя
механизма блокировок, включающего возможность блокирования по чтению и по записи.
Поддерживаются разные уровни детализации (гранулированности) блокировок от уровня
страниц внешней памяти базы данных до конфигураций (указываемых программистом групп
объектов).
Надежность хранения данных обеспечивается за счет поддержания журнала
произведенных изменений. Подсистема управления транзакциями отвечает за журнализацию
всех произведенных изменений на основе протокола WAL (Write Agead Log – упреждающей записи в
журнал). Дополнительно поддерживается архивный журнал, в котором авторизованный
пользователь может произвести архивное копирование базы данных.
Имеется средство поддержки версий, которое обеспечивает возможность коллективной
работы с базами данных на основе механизмов check-in /check-out . На этом подходе основывается
поддержка долгих транзакций. Для каждой конфигурации объектов можно создать историю
версий, независимую от типов объектов.
В ObjectStore стабильность хранения объектов поддерживается за счет наличия именованных
корневых стабильных объектов класса база данных. База данных создается с помощью
вызова метода new этого класса. Имеются методы для открытия и закрытия базы данных. Кроме
того, в классе содержатся методы для создания стабильных корневых объектов, обычно
являющихся коллекциями, в которых размещаются стабильные объекты.
Поддерживаются языки C , C++ и Smaltalk. Свойство стабильности обеспечивается за счет
включения в библиотеку классов специальных системных классов. Имеются классы,
поддерживающие коллекции – списки, множества, мультимножества и массивы. Методы этих
классов поддерживают выборку объектов из коллекций, вставку и удаление объектов.
Поддерживаются шлюзовые объекты, поддерживающие доступ к реляционным данным, а также
инструментальные средства для отображения реляционной схемы в эквивалентное объектно-ориентированное
представление. Таким образом, с реляционными базами данных можно работать в интерфейсе
ODBC на основе SQL или в собственном интерфейсе ObjectStore.
Objectivity/DB
Компания Objectivity (www.objectivity.com) была образована в 1988 г. В
1990 г. была выпущена первая версия системы, которая представляла собой распределенную
СУБД, основанную на использовании объектной технологии, высокопропускных локальных
сетей и симметричных мультипроцессоров. Система работает на всех основных UNIX-платформах
и в среде Windows.
Система основана на клиент-серверной архитектуре, в которой единицей обмена между
сервером и клиентом является страница базы данных. Тем самым многие системные функции,
включая кэширование, поиск объектов и преобразование их форматов, выполняются на
стороне клиента. Объектные идентификаторы представляются в 64-разрядном формате, что
обеспечивает потенциальную возможность работы со сверхбольшими базами данных.
Поддерживается четырехуровневая структура хранения данных. Объекты содержатся в
контейнерах, каждый из которых представляет собой часть локальной базы данных.
Локальные же базы данных могут комбинироваться в федеративную (распределенную) базу
данных. Надежность хранения данных поддерживается механизмом репликации.
Обеспечивается возможность изменения классов и автоматического образования новых
версий существующих объектов. Поддерживается механизм управления иерархиями версий
объектов.
Допускаются как короткие, так и долгие транзакции. Управление короткими транзакциями
основано на синхронизационных блокировках и распознавании тупиков. Долгие транзакции
и коллективная работа с базами данных основаны на многоверсионности объектов и
механизме check-in /check-out.
В системе поддерживаются языки C++ и Smalltalk, но способы использования языков сильно
различаются. Это относится и к механизмам стабильности, и к средствам определения
данных. В среде C++ стабильными являются объекты всех классов, являющихся наследниками
специального системного класса. В среде Smalltalk стабильными являются все объекты,
достижимые от именованных корневых объектов-словарей. Соответственно, в Smalltalk для
удаления объектов используется механизм сборки мусора, а в C++ – явные операции.
Естественно, базы данных, управляемые Objectivity/DB, основаны на одной объектной модели.
Эта модель достаточно близка к модели ODMG и, в частности, включает возможность
определения двунаправленных связей. Поддерживается возможность управления
составными объектами с распространением на подобъекты операции удаления. Однако
способы определения данных в средах C ++ и Smalltalk различаются.
В C++ включено специальное расширение языка, предназначенное для определения данных.
Соответствующие конструкции обрабатываются специальным препроцессором, который
генерирует код C ++, содержащий соответствующие обращения к СУБД. В среде Smalltalk схема
базы данных определяется как набор классов Smalltalk. Другими словами, при использовании
Smalltalk приложения, работающие с базами данных Objectivity/DB, организуются более прозрачным
образом, чем в случае C++.
Имеется поддержка языка SQL/89 и, частично, SQL/92. Реляционный доступ к базам данных,
управляемых Objectivity/DB , возможен через интерактивный SQL-ориентированный интерфейс, через
имеющийся драйвер ODBC и через API.
Versant
С 1988 г. компания Versant (www.versant.com) предлагает решения,
основанные на хорошо масштабируемой объектно-ориентированной архитектуре и
принадлежащем компании алгоритме кэширования. ООСУБД Versant является одной из немногих
объектно-ориентированных систем, допускающих масштабирование уровня любого
предприятия. Решения на базе Versant применяются в телекоммуникациях, обороне, на
транспорте и т.д. Система работает как на основных UNIX-платформах, так и в среде Windows.
Архитектура Versant в большей степени ориентирована на логическое управления данными, т.е.
объектами, а не на физическое представление данных в виде, например, страниц.
Управление размещением объекта осуществляется системой способом, полностью
прозрачным для пользователей. Для поддержки локальных хранилищ объектов используется
кэширование.
Система обладает свойством отказоустойчивости. Для этого допускается синхронная
репликация базы данных на двух серверах, которые могут находиться в одной локальной
сети или разнесены в разные точки глобальной сети. В одной базе данных Versant может
храниться около трехсот триллионов объектов, размер каждого из которых неограничен.
Для архивации данных может использоваться третичная внешняя память с автоматическим
оповещением оператора в случае потребности извлечения объектов из архива.
Поддерживаются кластеры совместно используемых объектов, причем встроенные объекты
хранятся внутри своих объектов-предков, что способствует уменьшению уровня
фрагментации памяти. Кластеризация применяется и при внешнем кэшировании. Кроме того,
в системе Versant поддерживается возможность использования персональных баз данных,
установленных на мобильных компьютерах. Они могут быть отсоединены от сервера
центральной базы данных, использоваться автономно и зафиксировать свои изменения в
центральной базе данных после восстановления соединения.
Управление транзакциями основывается, главным образом, на синхронизационных
блокировках на уровне объектов, хотя возможны блокировки классов и версий объектов.
Имеется целый ряд разновидностей блокировок: короткие блокировки для коротких
транзакций, стабильные блокировки для долгих транзакций и т.д. Допускается даже
возможность расширения модели блокировки правилами, желательными для пользователей.
Система избегает тупиковых синхронизационных ситуаций, не удовлетворяя запросы на
блокировку, которые могут привести к тупику.
Фиксация распределенных транзакций основывается на двухфазном протоколе фиксации.
Поддерживаются частичная фиксация кэшей, механизмы контрольных точек и точек
сохранения. Обеспечивается и возможность образования вложенных транзакций. При
реализации долгих транзакций используется механизм check-in /check-out с установкой
стабильной блокировки на требуемые объекты, предотвращающей доступ к этим объектам со
стороны других транзакций до завершения данной долгой транзакции.
Имеется возможность регистрации на сервере событий, которые интересуют приложения.
При регистрации серверу сообщается вид события и операция, которую следует выполнять
при возникновении события. К событиям, которые разрешается регистрировать, относятся
обновление и удаление классов, создание, обновление и удаление объектов.
Для повышения надежности хранения баз данных поддерживаются два вида журналов –
логический и физический. При необходимости восстановления базы данных по архивной
копии все зафиксированные к моменту сбоя транзакции повторно воспроизводятся по
логическому журналу.
Обеспечивается ссылочная целостность базы данных и прозрачность месторасположения
объектов в распределенной среде. Объекты могут мигрировать по узлам сети, что
способствует балансировке нагрузки, и оставаться полностью доступными для приложений.
Допускается динамическая модификация классов, приводящая к автоматической
модификации всех существующих в базе данных объектов этих классов. При этом система
все время остается в рабочем состоянии, и приложения продолжают выполняться.
Поддерживается развитый механизм версий. По известной версии объекта можно получить
доступ к его предкам, потомкам и братьям.
Для представления связей между объектами базы данных используется единый стабильный
указательный тип. В системе поддерживаются скрытые от пользователей преобразования
указателей базы данных в обычные указатели C++ и наоборот. Поэтому объекты создаются и
ликвидируются с помощью стандартных конструкторов и деструкторов классов.
Для программирования можно использовать языки C++ и Smalltalk, причем безо всяких
расширений. Поддерживаются возможности, специфичные для работы с базами данных.
Например, имеется средство автоматической генерации схемы базы данных прямо по файлам
заголовков C++. Это позволяет обойтись без использования специализированных
препроцессоров или компиляторов. Специальные системные классы позволяют работать со
всеми разновидностями типов коллекций, специфицированными в стандарте ODMG. Любой
объект, созданный в среде C++, доступен в среде Smalltalk и наоборот.
Запросы к базам данных Versant можно задавать с помощью специального системного класса,
позволяющего обходить объекты коллекций. Поддерживается расширенный вариант SQL/89.
Имеется драйвер ODBC. Обеспечивается доступ из среды Versant к внешним реляционным базам
данных.
Выводы по ООСУБД
Описанные системы технически весьма разнородны. В общем смысле все системы
соответствуют базовой модели ODMG, но следует обратить внимание, что крайне редко в
качестве языка запросов поддерживается OQL, и ни в одной системе не поддерживается ODL.
Ни одна из компаний, производящих ООСУБД, так и не смогла набрать критическую массу,
достаточную для того, чтобы стать лидером, диктующим моду в данной области (как это
произошло с IBM и Oracle в области SQL-ориентированных СУБД). Крупные компьютерные компании
так и не решились приобрести какой-нибудь продукт ООСУБД, чтобы развивать его и
продвигать на рынке.
Сравнение реляционных и объектно-ориентированных баз данных
Реляционные базы данных
Недостатки
- Сложность описания связей объектов в их представлениях в базе данных. Подчас
естественная и понятная связь объектов реального мира представлена в БД очень
сложно (многоступенчатая связь).
- «Разреженность» таблиц. В связи с тем, что БД универсальна, предназначена для
хранения всех возможных атрибутов объектов, таблицы содержат множество полей и
очень часто подавляющая часть из них оказываются незаполненными. Хранение
разнотипных данных скопом в каком-нибудь универсальном поле сводит на нет
преимущества реляционных баз данных и их совершенный математический аппарат. За
быстродействие приходится расплачиваться удобством: в большой таблице сложнее
разбираться.
- Необходимость обратной совместимости с предыдущими версиями тормозит развитие РБД
(это обстоятельство нельзя назвать совсем уж минусом).
Достоинства
- Строгость структуры данных (соблюдение целостности).
- Высокая скорость работы.
- Развитая алгебра.
- Большие объемы БД.
Объектно-ориентированные базы данных
Недостатки
- Снижение производительности на больших объемах данных.
- Вынужденная простота БД (имеющиеся технологии не позволяют организовывать
достаточно сложные системы).
- Отсутствие единого стандарта.
Достоинства
- Разделение работы клиентского приложения с данными и способом их хранения в БД (высокий
уровень абстракции).
- Упрощение модели БД.
- Возможность повторного использования.
- Простота организации отношений «многие-ко-многим».
Ссылки на источники
- Объектно-ориентированные базы данных -основные концепции, организация и управление:
краткий обзор (www.msk.nestor.minsk.by/kg/2005/32/kg53209.html)
- Объектно-ориентированные базы данных: достижения и проблемы (www.osp.ru/os/2004/03/184042/)
- Универсальная база данных (www.stikriz.narod.ru)
- Реляционные, древовидные и объектно-ориентированные базы данных (www.inftech.webservis.ru/it/database/oo/ar3.html)
- Три манифеста баз данных: ретроспектива и перспективы (www.citforum.ru/database/articles/manifests/)
- Lotus Notes / Domino (www.ibm.com/software/ru/campaign/lotus/)
- Что такое Lotus Domino и Notes и как они работают? (www.compress.ru/Archive/CP/2000/5/15/)
- Все о Lotus Notes / Domino (www.notesnet.ru/nn/notesnet.nsf)
|